GeoParquet in QGIS – smaller & faster files for the win!
tldr; Tired of working with large CSV files? Give GeoParquet a try!
“Parquet is a powerful column-oriented data format, built from the ground up to as a modern alternative to CSV files.” https://geoparquet.org/
(Geo)Parquet is both smaller and faster than CSV. Additionally, (Geo)Parquet columns are typed. Text, numeric values, dates, geometries retain their data types. GeoParquet also stores CRS information and support in GIS solutions is growing.
I’ll be giving a quick overview using AIS data in GeoPandas 1.0.1 (with pyarrow) and QGIS 3.38 (with GDAL 3.9.2).
File size
The example AIS dataset for this demo contains ~10 million rows with 22 columns. I’ve converted the original zipped CSV into GeoPackage and GeoParquet using GeoPandas to illustrate the huge difference in file size: ~470 MB for GeoParquet and zipped CSV, 1.6 GB for CSV, and a whopping 2.6 GB for GeoPackage:

Reading performance
Pandas and GeoPandas both support selective reading of files, i.e. we can specify the specific columns to be loaded. This does speed up reading, even from CSV files:
| Whole file | Selected columns | |
| CSV | 27.9 s | 13.1 s |
| Geopackage | 2min 12s  | 20.2 s |
| GeoParquet | 7.2 s | 4.1 s |
Indeed, reading the whole GeoPackage is getting quite painful.
Here’s the code I used for timing the read times:

As you can see, these times include the creation of the GeoPandas.GeoDataFrame.
If we don’t need a GeoDataFrame, we can read the files even faster:
Non-spatial DataFrames
GeoParquet files can be read by non-GIS tools, such as Pandas. This makes it easier to collaborate with people who may not be familiar with geospatial data stacks.
And reading plain DataFrames is much faster than creating GeoDataFrames:

But back to GIS …
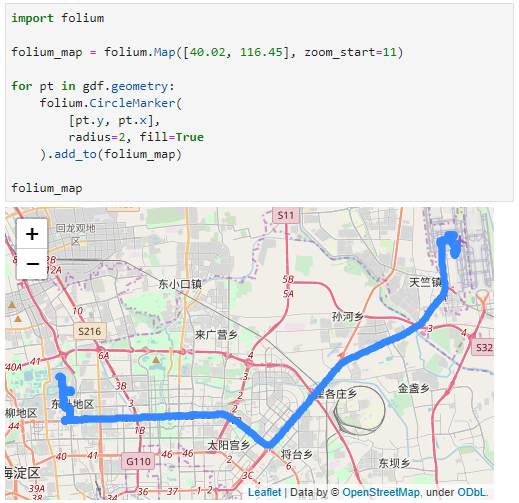
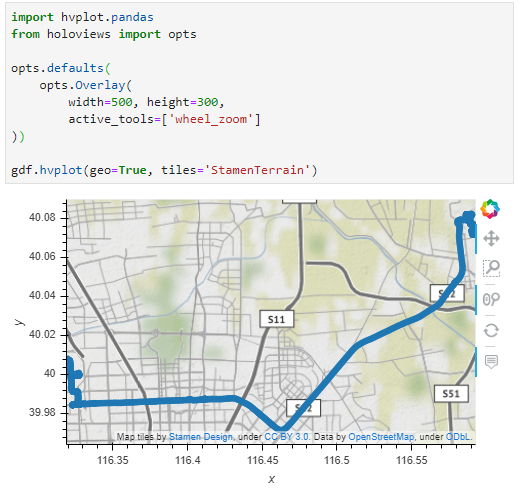
GeoParquet in QGIS
In QGIS, GeoParquet files can be loaded like any other vector layer, thanks to GDAL:

Loading the GeoParquet and GeoPackage files is pretty quick, especially if we zoom into a small region of interest (even though, unfortunately, it doesn’t seem possible to restrict the columns to further speed up loading). Loading the CSV, however, is pretty painful due to the lack of spatial indexing, which becomes apparent very quickly in the direct comparison:

As far as I can tell, my QGIS 3.38 ‘Grenoble’ does not support writing to or editing of GeoParquet files. So I’m limited to reading GeoParquet for now.
However, seeing how much smaller GeoParquets are compared to GeoPackages (and also faster to write), I hope that we will soon get the option to export to GeoParquet.
For now, I’ll start by converting my large CSV files to GeoParquet using GeoPandas.
More reading
If you’re into GeoJSON and/or PyGeoAPI, check out Joana Simoes’ post: “Navigating GeoParquet: Lessons Learned from the eMOTIONAL Cities Project”
And if you want to see a global dataset example, have a look at Matt Travis’ presentation using Overture data: