OSM turn restriction QA with QGIS
Wrong navigation instructions can be annoying and sometimes even dangerous, but they happen. No dataset is free of errors. That’s why it’s important to assess the quality of datasets. One specific use case I previously presented at FOSS4G 2013 is the quality assessment of turn restrictions in OSM, which influence vehicle routing results.
The main idea is to compare OSM to another data source. For this example, I used turn restriction data from the City of Toronto. Of the more than 70,000 features in this dataset, I extracted a sample of about 500 turn restrictions around Ryerson University, which I had the pleasure of visiting in 2014.
As you can see from the following screenshot, OSM and the city’s dataset agree on 420 of 504 restrictions (83%), while 36 cases (7%) are in clear disagreement. The remaining cases require further visual inspection.

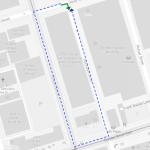
The following two examples show one case where the turn restriction is modelled in both datasets (on the left) and one case where OSM does not agree with the city data (on the right).
In the first case, the turn restriction (short green arrow) tells us that cars are not allowed to turn right at this location. An OSM-based router (here I used OpenRouteService.org) therefore finds a route (blue dashed arrow) which avoids the forbidden turn. In the second case, the router does not avoid the forbidden turn. We have to conclude that one of the two datasets is wrong.

If you want to learn more about the methodology, please check Graser, A., Straub, M., & Dragaschnig, M. (2014). Towards an open source analysis toolbox for street network comparison: indicators, tools and results of a comparison of OSM and the official Austrian reference graph. Transactions in GIS, 18(4), 510-526. doi:10.1111/tgis.12061.
Interestingly, the disagreement in the second example has been fixed by a recent edit (only 14 hours ago). We can see this in the OSM way history, which reveals that the line direction has been switched, but this change hasn’t made it into the routing databases yet:


This leads to the funny situation that the oneway is correctly displayed on the map but seemingly ignored by the routers:

To evaluate the results of the automatic analysis, I wrote a QGIS script, which allows me to step through the results and visually compare turn restrictions and routing results. It provides a function called next() which updates a project variable called myvar. This project variable controls which features (i.e. turn restriction and associated route) are rendered. Finally, the script zooms to the route feature:
def next():
f = features.next()
id = f['TURN_ID']
print "Going to %s" % (id)
QgsExpressionContextUtils.setProjectVariable('myvar',id)
iface.mapCanvas().zoomToFeatureExtent(f.geometry().boundingBox())
if iface.mapCanvas().scale() < 500:
iface.mapCanvas().zoomScale(500)
layer = iface.activeLayer()
features = layer.getFeatures()
next()
You can see it in action here:
I’d love to see this as an interactive web map where users can have a look at all results, compare with other routing services – or ideally the real world – and finally fix OSM where necessary.
This work has been in the making for a while. I’d like to thank the team of OpenRouteService.org who’s routing service I used (and who recently added support for North America) as well as my colleagues at Ryerson University in Toronto, who pointed me towards Toronto’s open data.