






Movement data in GIS: issues & ideas
Since I’ve started working, transport and movement data have been at the core of many of my projects. The spatial nature of movement data makes it interesting for GIScience but typical GIS tools are not a particularly good match.
Dealing with the temporal dynamics of geographic processes is one of the grand challenges for Geographic Information Science. Geographic Information Systems (GIS) and related spatial analysis methods are quite adept at handling spatial dimensions of patterns and processes, but the temporal and coupled space-time attributes of phenomena are difficult to represent and examine with contemporary GIS. (Dr. Paul M. Torrens, Center for Urban Science + Progress, New York University)
It’s still a hot topic right now, as the variety of related publications and events illustrates. For example, just this month, there is an Animove two-week professional training course (18–30 September 2016, Max-Planck Institute for Ornithology, Lake Konstanz) as well as the GIScience 2016 Workshop on Analysis of Movement Data (27 September 2016, Montreal, Canada).
Space-time cubes and animations are classics when it comes to visualizing movement data in GIS. They can be used for some visual analysis but have their limitations, particularly when it comes to working with and trying to understand lots of data. Visualization and analysis of spatio-temporal data in GIS is further complicated by the fact that the temporal information is not standardized in most GIS data formats. (Some notable exceptions of formats that do support time by design are GPX and NetCDF but those aren’t really first-class citizens in current desktop GIS.)
Most commonly, movement data is modeled as points (x,y, and optionally z) with a timestamp, object or tracker id, and potential additional info, such as speed, status, heading, and so on. With this data model, even simple questions like “Find all tracks that start in area A and end in area B” can become a real pain in “vanilla” desktop GIS. Even if the points come with a sequence number, which makes it easy to identify the start point, getting the end point is tricky without some custom code or queries. That’s why I have been storing the points in databases in order to at least have the powers of SQL to deal with the data. Even so, most queries were still painfully complex and performance unsatisfactory.
So I reached out to the Twitterverse asking for pointers towards moving objects database extensions for PostGIS and @bitnerd, @pwramsey, @hruske, and others replied. Amongst other useful tips, they pointed me towards the new temporal support, which ships with PostGIS 2.2. It includes the following neat functions:
- ST_IsValidTrajectory — Returns true if the geometry is a valid trajectory.
- ST_ClosestPointOfApproach — Returns the measure at which points interpolated along two lines are closest.
- ST_DistanceCPA — Returns the distance between closest points of approach in two trajectories.
- ST_CPAWithin — Returns true if the trajectories’ closest points of approach are within the specified distance.
Instead of points, these functions expect trajectories that are stored as LinestringM (or LinestringZM) where M is the time dimension. This approach makes many analyses considerably easier to handle. For example, clustering trajectory start and end locations and identifying the most common connections:
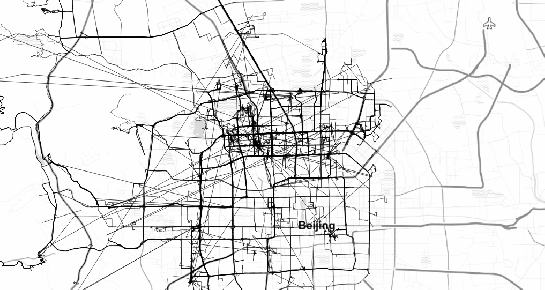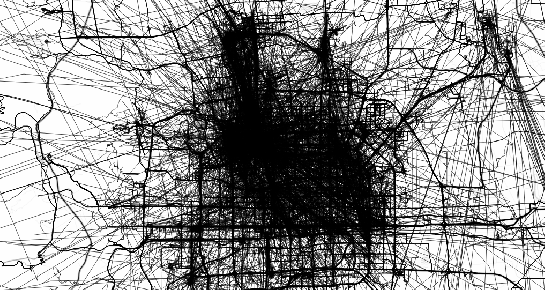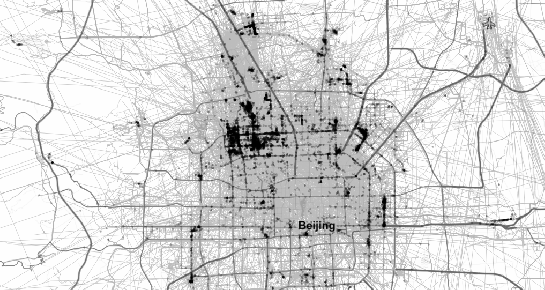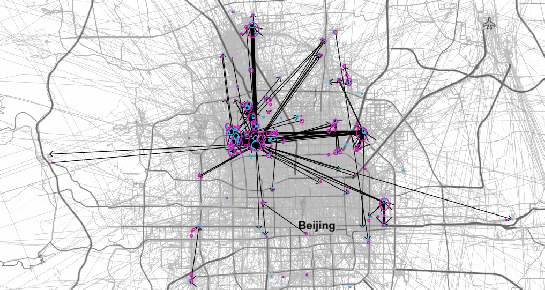
(data credits: GeoLife project)
Overall, it’s an interesting and promising approach but there are still some open questions I’ll have to look into, such as: Is there an efficient way to store additional info for each location along the trajectory (e.g. instantaneous speed or other status)? How well do desktop GIS play with LinestringM data and what’s the overhead of dealing with it?




