QGIS Snapping improvements
A few months ago, we proposed to the QGIS grant program to make improvements to the snap cache in QGIS. The community vote selected our project which was funded by QGIS.org. Developments are now mostly finished.
In short, snapping is crucial for editing geospatial features. It is the only way to ensuring they are topologically related, ie, connected vertices have exactly the same coordinates even if manual digitizing on screen is imprecise by nature. Snapping correctly supposes QGIS have in memory an indexed cache of the geometries to snap to. And maintainting this cache when data is modified, sometimes by another user or database logic, can be a real challenge. This it exactly what this work adresses.
The proposal was divided into two different tasks:
- Manage circular dependencies
- Relax the snap cache index build
Manage cicular data dependencies
Data dependencies
Data dependency is an existing feature that allows you to configure QGIS to reload layers (and their snapping cache) when a layer is modified.
It is useful when you store your data in a database and you set up triggers to maintain consistency between the different tables of your data model.
For instance, say you have topological informations containing lines and nodes. Nodes are part of lines and lines go through nodes. Then, you move a node in QGIS, and save your modifications to the database. In order to keep the data consistent, a trigger updates the geometry of the line going through the modified node.
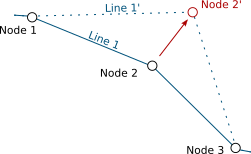
Node 2 is modified, Line 1 is updated accordingly
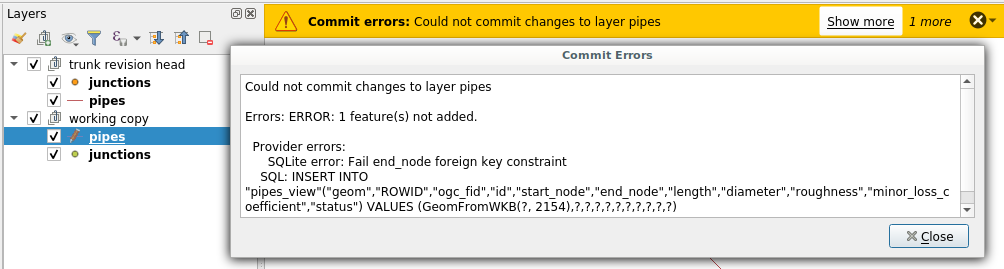
QGIS, as a database client, has no information that the line layer currently displayed in the canvas needs to be refreshed after the trigger. Although the map canvas will be up to date, because QGIS fetches data for display without any caching system, the snapping cache is not and you’ll end up with ghost snapping highlights issues.
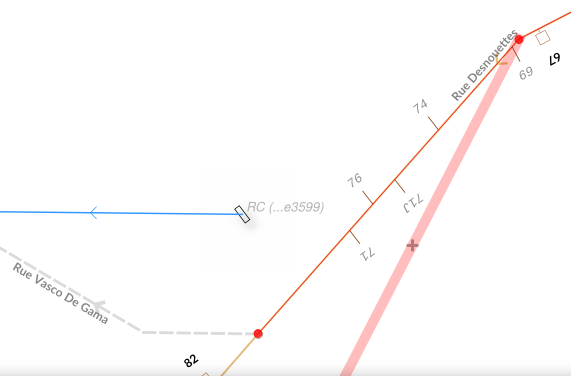
Snapping highlights (light red) differ from real line (orange)
Defining a dependency between nodes and lines layers tells QGIS that it has to refresh the line layer when a node is modified.
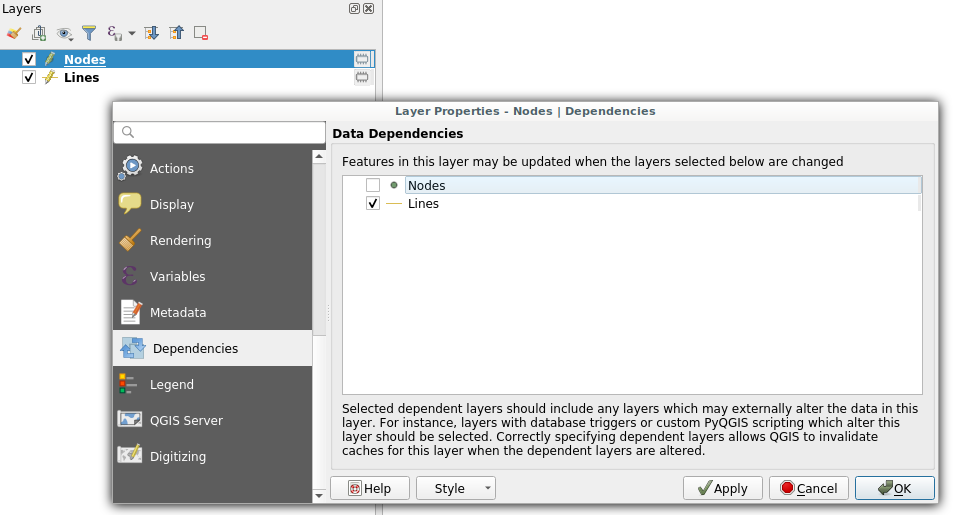 Dependencies configuration: Lines layer will be refreshed whenever Nodes layer is modified
Dependencies configuration: Lines layer will be refreshed whenever Nodes layer is modified
It also have to work the other way, modifying a line should update the nodes to ensure they still are on the line.
Circular data dependencies
So here we are, lines depend on nodes which depend on lines which depend on nodes which…

That’s what circular dependencies is about. This specific behavior was previously forbidden and needed a special way to deal with it. Thanks to this recent development, it is now possible.
It’s also possible to add the layer itself as one of its own dependencies. It helps dealing with specific cases where one feature modification could lead to a modification of another feature in the same layer (to keep consistency on road networks for instance).
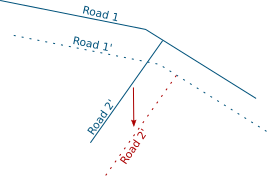
Road 2 is modified, Road 1 is updated accordingly
This feature is available in the next QGIS LTR version 3.10.
Relax the snapping cache index build
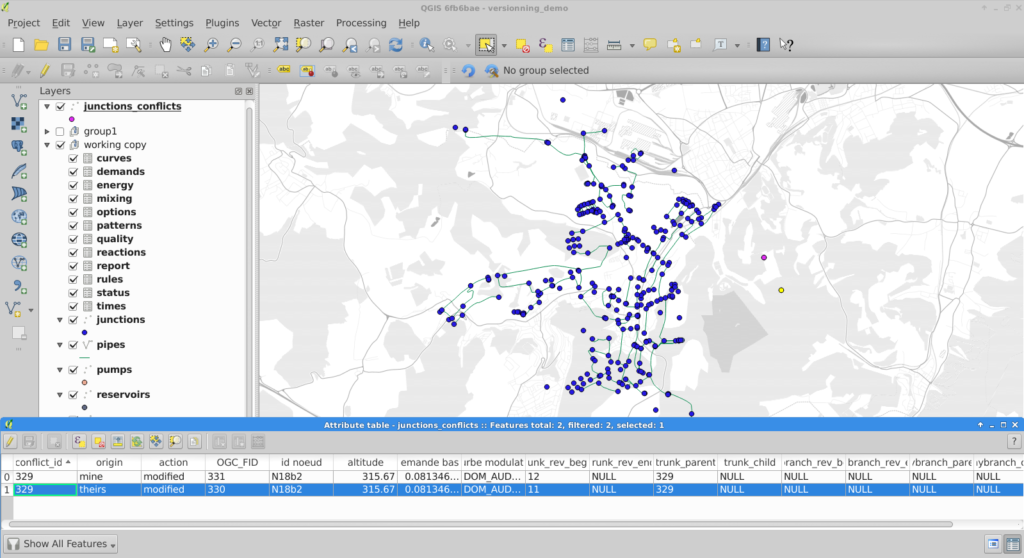
If you work in QGIS with huge projects displaying a lot of vector data, and you enable snapping while editing these data, you probably already met this dialog:
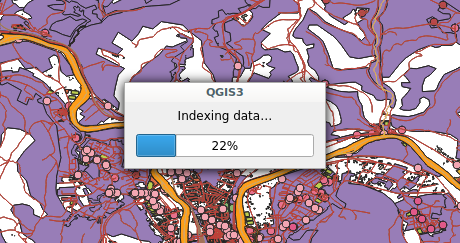 Snap indexing dialog
Snap indexing dialog
This dialog informs you that data are currently being indexed so you can snap on them while you will edit feature geometry. And for big projects, this dialog can last for a really long time. Let’s work on speeding it up!
What’s a snap index?
Let’s say you want to move a line and snap it onto another one. While you drag your line with the mouse, QGIS will look for an existing geometry beneath the mouse cursor (with a certain pixel tolerance) every time you move your mouse. Without spatial index, QGIS will have to go through every geometry in your layer to check if the given geometry is beneath the cursor position. This would be very ineffective.
In order to prevent this, QGIS keeps an index where vector data are stored in a way that it can quickly find out what geometry is beneath the mouse cursor. The building of this data structure takes time and that is what the progress dialog is about.
Firstly: Parallelize snap index build
If you want to be able to snap on all layers in your project, then QGIS will have to build one snap index for each layer. This operation was made sequentially meaning that if you have for instance 20 layers and the index building last approximatively 3 seconds for each, then the whole index building will last 1 minute. We made modifications to QGIS so that index building could be done in parallel. As a result, the total index building time could theoretically be 3 seconds!
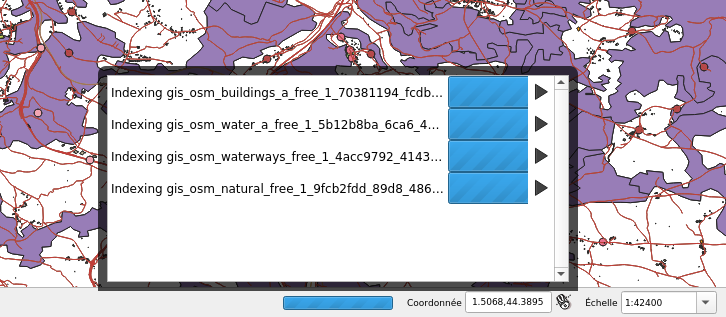 4 layers snap index being built in parallel
4 layers snap index being built in parallel
However, parallel operations are limited by the number of CPU cores of your machine, meaning that if you have 4 cores (core i7 for instance) then the total time will be up to 4 times faster than when the building is sequential (and last 15 seconds in our example).
Secondly: relax the snap build
For big projects, parallelizing index building is not enough and still takes too much time. Futhermore, to reduce snap index building, an existing optimisation was to build the spatial index for a specific area of interest (determined according to the displayed area and layer size). As a consequence, when you’ve done waiting for an index currently building and you move the map or zoom in/out, you could possibly trigger another snap index building and wait again.
So, the idea was to avoid waiting at all. Snap index is now built whenever it needs to (when you first enable snapping, when you move or zoom) but the user doesn’t have to wait for the build to be over and can continue what it was doing (creating feature, moving…). Snapping highlights will be missing when the index is currently being built and will appear gradually as soon as they finished. That’s what we call the relaxing mode.
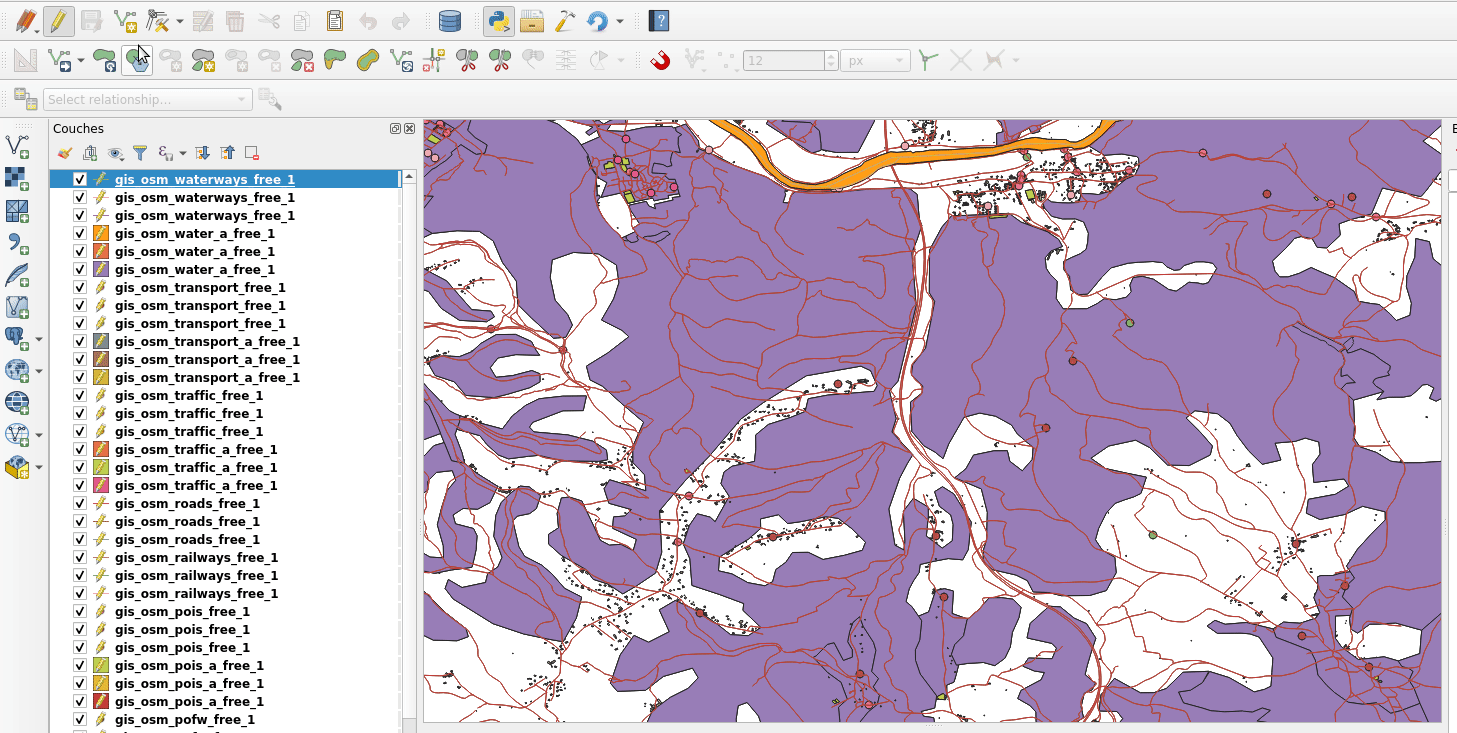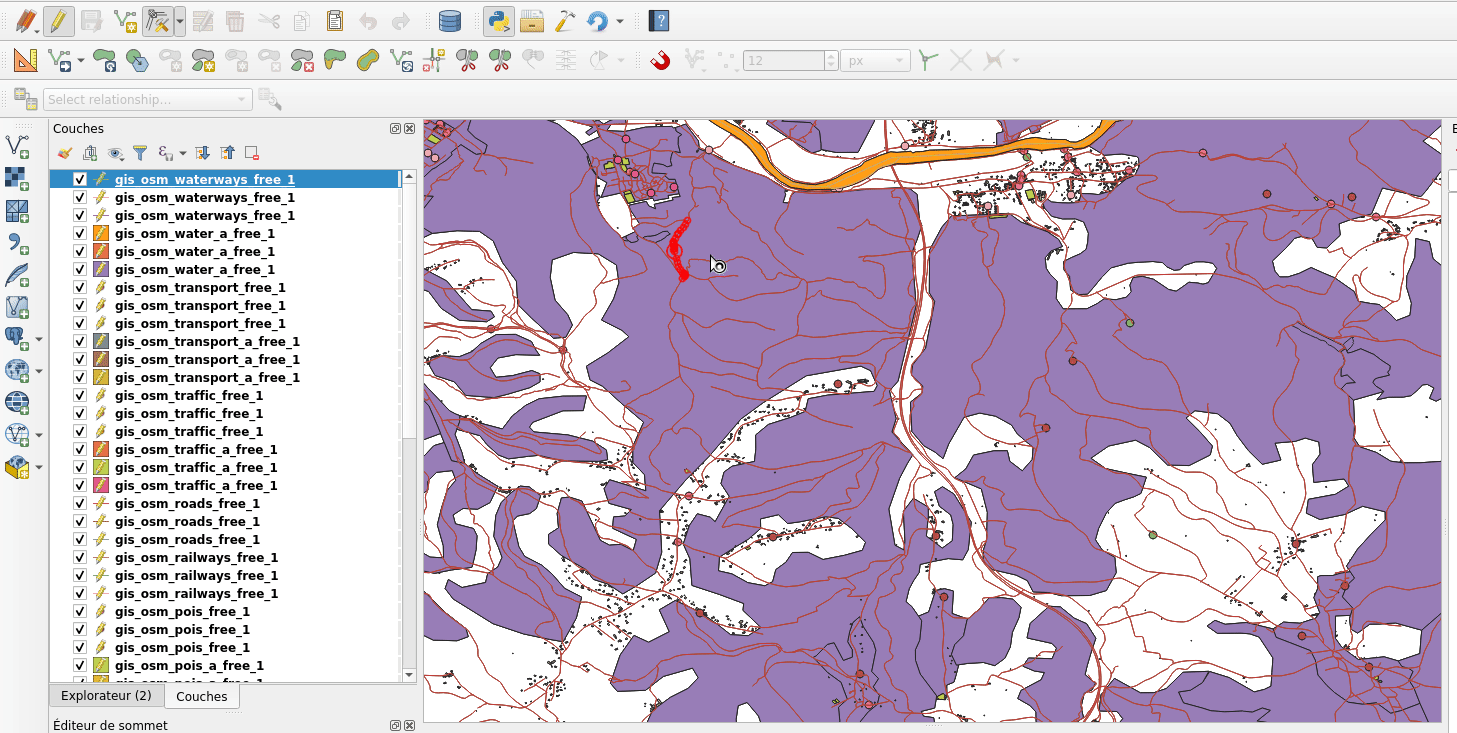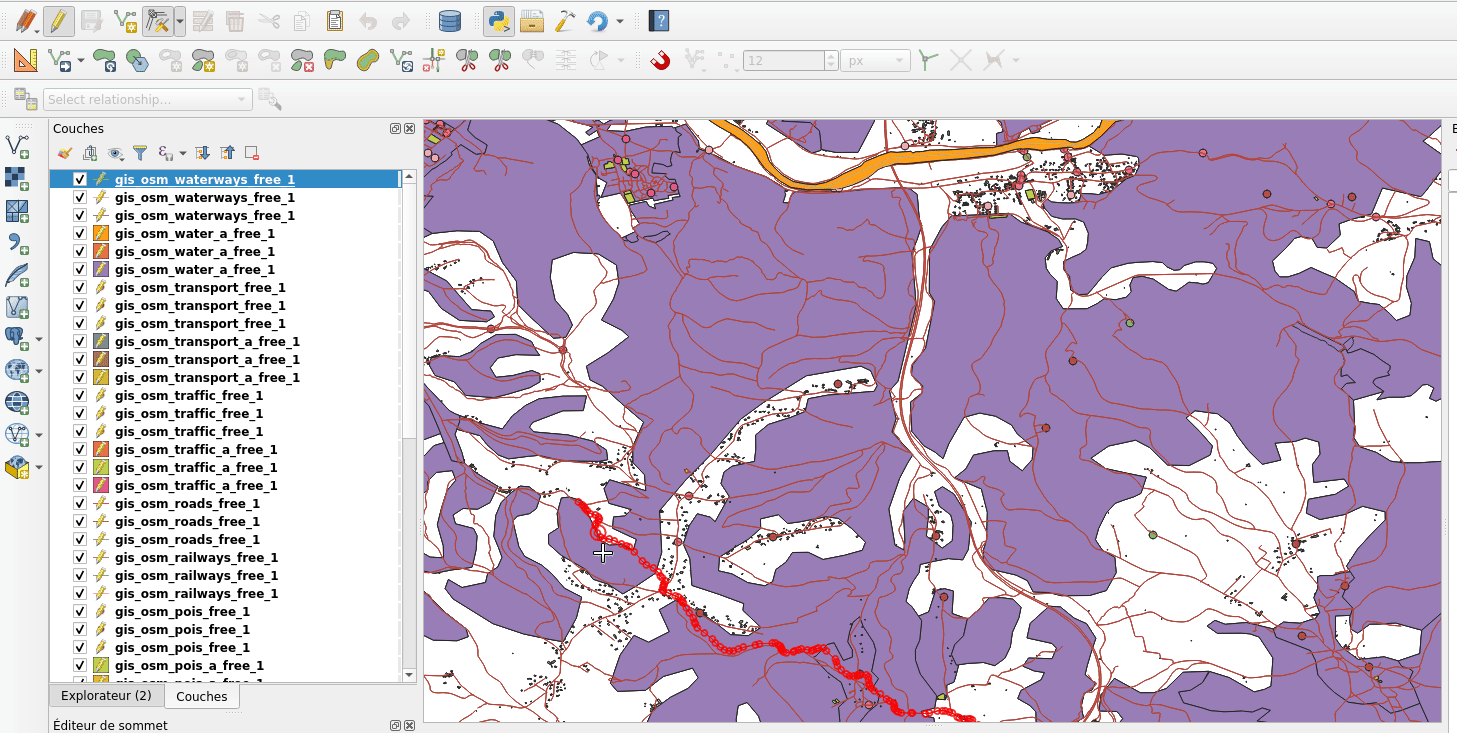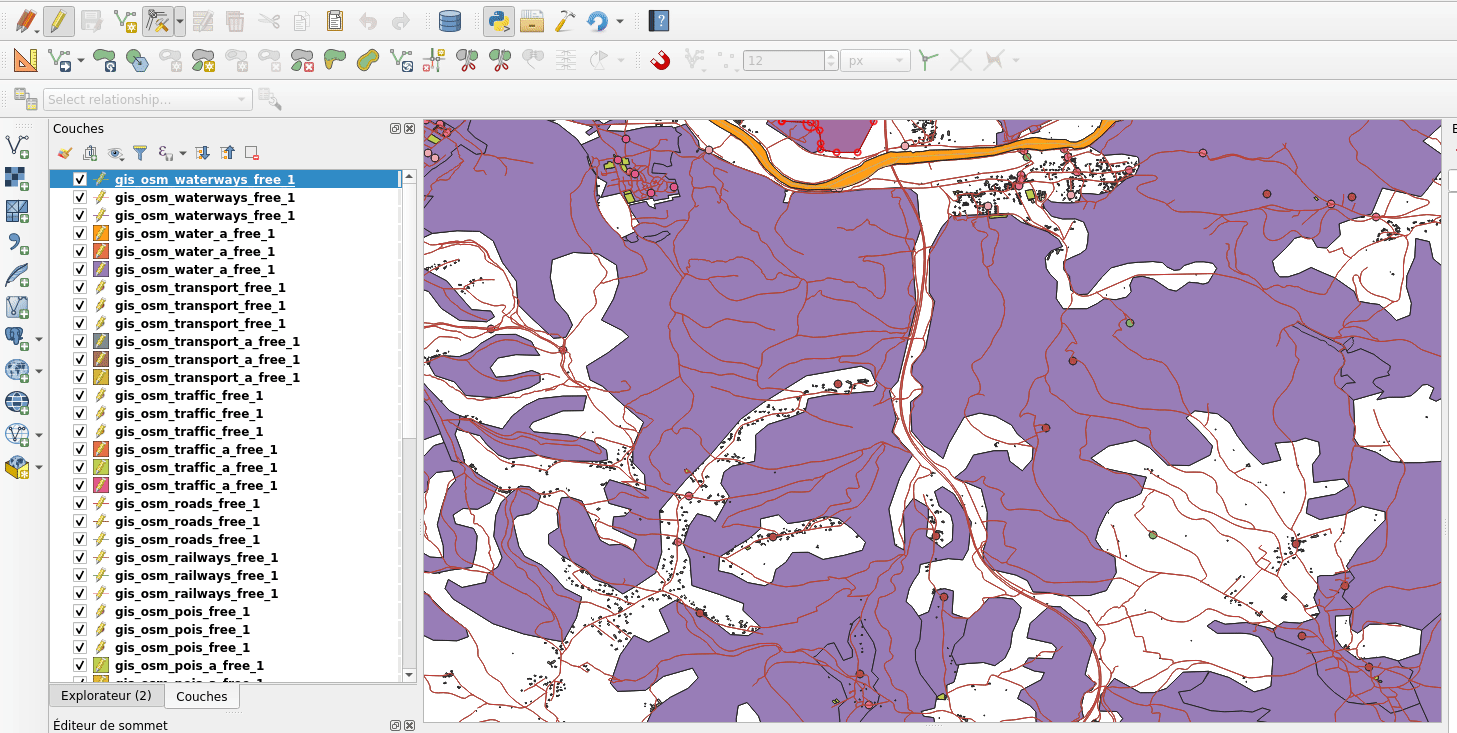
No waiting dialog, snapping highlights appears as soon as snap index is ready
This feature has been merged into current QGIS master and will be present in future QGIS 3.12 release. We keep working on this feature in order to make it more stable and efficient.
What’s next
We’ll continue to improve this feature in the coming days, if you have the chance to test it and encounter issues please let us know on the QGIS tracker. If you think about a missing feature or just want to know more about QGIS, feel free to contact us at [email protected]. And please have a look at our support offering for QGIS.
Many thanks to QGIS grant program for funding these new features. Thanks also to all the people involved in reviewing the code and helping to better understand the existing mechanism.