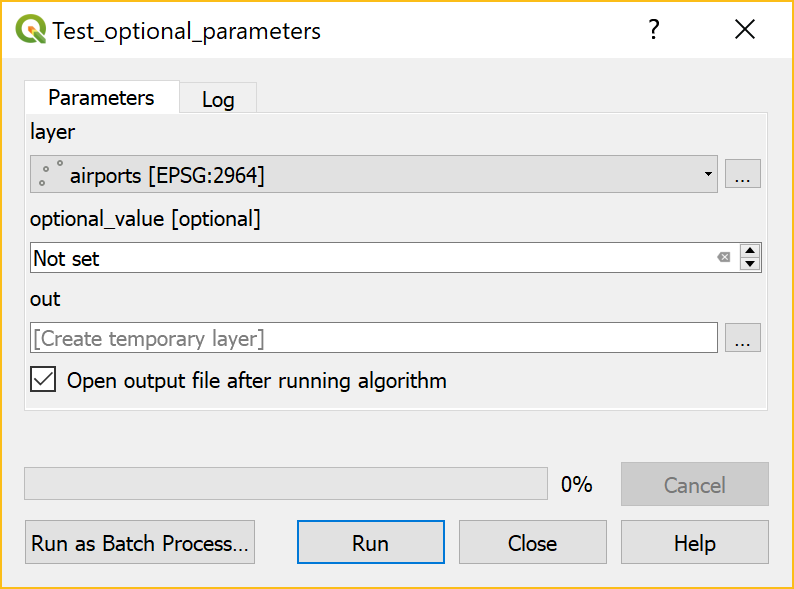
Scalable spatial vector data processing
Working with movement data analysis, I’ve banged my head against performance issues every once in a while. For example, PostgreSQL – and therefore PostGIS – run queries in a single thread of execution. This is now changing, with more and more functionality being parallelized. PostgreSQL version 9.6 (released on 2016-09-29) included important steps towards parallelization, including parallel execution of sequential scans, joins and aggregates. Still, there is no parallel processing in PostGIS so far (but it is under development as described by Paul Ramsey in his posts “Parallel PostGIS II” and “PostGIS Scaling” from late 2017).
At the FOSS4G2016 in Bonn, I had the pleasure to chat with Shoaib Burq who ran the “An intro to Apache PySpark for Big Data GeoAnalysis” workshop. Back home, I downloaded the workshop material and gave it a try but since I wanted a scalable system for storing, analyzing, and visualizing spatial data, it didn’t really seem to fit the bill.
Around one year ago, my search grew more serious since we needed a solution that would support our research group’s new projects where we expected to work with billions of location records (timestamped points and associated attributes). I was happy to find that the fine folks at LocationTech have some very promising open source projects focusing on big spatial data, most notably GeoMesa and GeoWave. Both tools take care of storing and querying big spatio-temporal datasets and integrate into GeoServer for publication and visualization. (A good – if already slightly outdated – comparison of the two has been published by Azavea.)
My understanding at the time was that GeoMesa had a stronger vector data focus while GeoWave was more focused on raster data. This lead me to try out GeoMesa. I published my first steps in “Getting started with GeoMesa using Geodocker” but things only really started to take off once I joined the developer chats and was pointed towards CCRI’s cloud-local “a collection of bash scripts to set up a single-node cloud on your desktop, laptop, or NUC”. This enabled me to skip most of the setup pains and go straight to testing GeoMesa’s functionality.
The learning curve is rather significant: numerous big data stack components (including HDFS, Accumulo, and GeoMesa), a most likely new language (Scala), as well as the Spark computing system require some getting used to. One thing that softened the blow is the fact that writing queries in SparkSQL + GeoMesa is pretty close to writing PostGIS queries. It’s also rather impressive to browse hundreds of millions of points by connecting QGIS TimeManager to a GeoServer WMS-T with GeoMesa backend.

Spatial big data stack with GeoMesa
One of the first big datasets I’ve tested are taxi floating car data (FCD). At one million records per day, the three years in the following example amount to a total of around one billion timestamped points. A query for travel times between arbitrary start and destination locations took a couple of seconds:

Travel time statistics with GeoMesa (left) compared to Google Maps predictions (right)
Besides travel time predictions, I’m also looking into the potential for predicting future movement. After all, it seems not unreasonable to assume that an object would move in a similar fashion as other similar objects did in the past.

Early results of a proof of concept for GeoMesa based movement prediction
Big spatial data – both vector and raster – are an exciting challenge bringing new tools and approaches to our ever expanding spatial toolset. Development of components in open source big data stacks is rapid – not unlike the development speed of QGIS. This can make it challenging to keep up but it also holds promises for continuous improvements and quick turn-around times.
If you are using GeoMesa to work with spatio-temporal data, I’d love to hear about your experiences.





 With support from
With support from