Today marks the 2.1 release of Trajectools for QGIS. This release adds multiple new algorithms and improvements. Since some improvements involve upstream MovingPandas functionality, I recommend to also update MovingPandas while you’re at it.
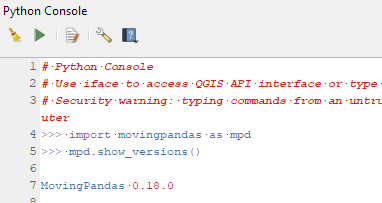
If you have installed QGIS and MovingPandas via conda / mamba, you can simply:
Afterwards, you can check that the library was correctly installed using:
import movingpandas as mpd mpd.show_versions()
Trajectools 2.1
The new Trajectools algorithms are:
Trajectory overlay — Intersect trajectories with polygon layer
Privacy — Home work attack (requires scikit-mobility)
This algorithm determines how easy it is to identify an individual in a dataset. In a home and work attack the adversary knows the coordinates of the two locations most frequently visited by an individual.
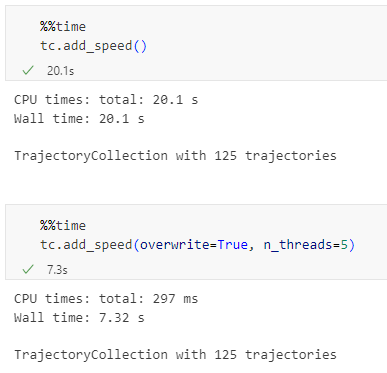
Furthermore, we have fixed issue with previously ignored minimum trajectory length settings.
Scikit-mobility and gtfs_functions are optional dependencies. You do not need to install them, if you do not want to use the corresponding algorithms. In any case, they can be installed using mamba and pip:
There are a couple of existing plugins that deal with GTFS. However, in my experience, they either don’t integrate with Processing and/or don’t provide the functions I was expecting.
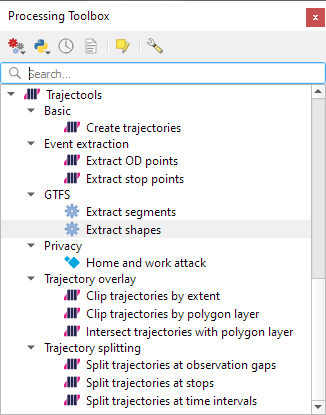
So far, we have two GTFS algorithms to cover essential public transport analysis needs:
The “Extract shapes” algorithm gives us the public transport routes:
The “Extract segments” algorithm has one more options. In addition to extracting the segments between public transport stops, it can also enrich the segments with the scheduled vehicle speeds:
Here you can see the scheduled speeds:
To show the stops, we can put marker line markers on the segment start and end locations:
The segments contain route information and stop names, so these can be extracted and used for labeling as well:
Today’s post is a QGIS Server update. It’s been a while (12 years ) since I last posted about QGIS Server. It would be an understatement to say that things have evolved since then, not least due to the development of Docker which, Wikipedia tells me, was released 11 years ago.
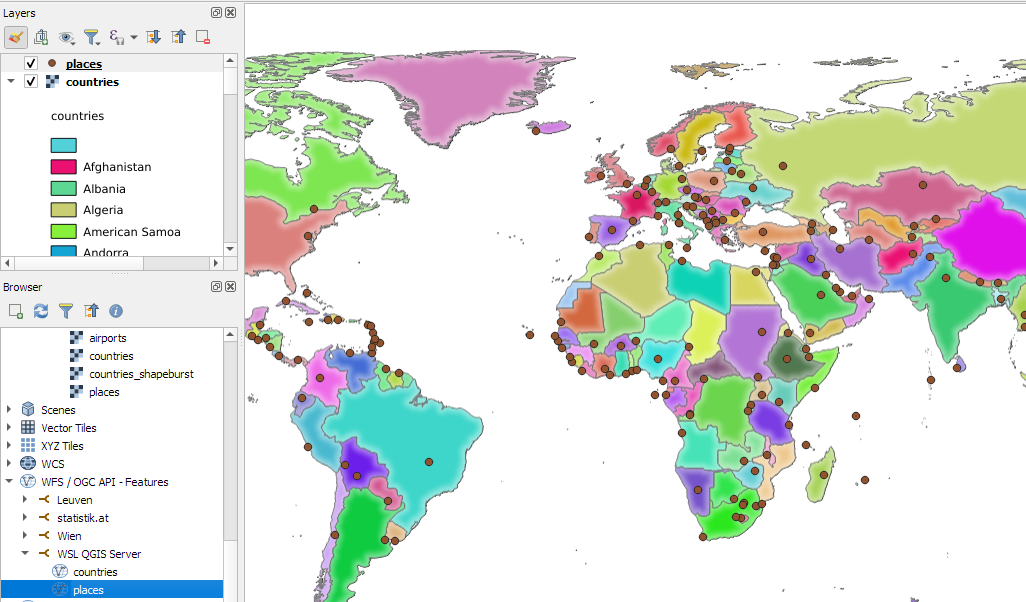
There have been multiple Docker images for QGIS Server provided by QGIS Community members over the years. Recently, OPENGIS.ch’s Docker image has been adopted as official QGIS Server image https://github.com/qgis/qgis-docker which aims to be a starting point for users to develop their own customized applications.
The following steps have been tested on Ubuntu (both native and in WSL).
Once Docker is set up, we can get the QGIS Server, e.g. for the LTR:
docker pull qgis/qgis-server:ltr
Now we only need to start it:
docker run -v $(pwd)/qgis-server-data:/io/data --name qgis-server -d -p 8010:80 qgis/qgis-server:ltr
Note how we are mapping the qgis-server-data directory in our current working directory to /io/data in the container. This is where we’ll put our QGIS project files.
If you instead get the error “<ServerException>Project file error. For OWS services: please provide a SERVICE and a MAP parameter pointing to a valid QGIS project file</ServerException>”, it probably means that the world.qgs file is not found in the qgis-server-data/world directory.
Today’s post is a quick introduction to pygeoapi, a Python server implementation of the OGC API suite of standards. OGC API provides many different standards but I’m particularly interested in OGC API – Processes which standardizes geospatial data processing functionality. pygeoapi implements this standard by providing a plugin architecture, thereby allowing developers to implement custom processing workflows in Python.
I’ll provide instructions for setting up and running pygeoapi on Windows using Powershell. The official docs show how to do this on Linux systems. The pygeoapi homepage prominently features instructions for installing the dev version. For first experiments, however, I’d recommend using a release version instead. So that’s what we’ll do here.
As a first step, lets install the latest release (0.16.1 at the time of writing) from conda-forge:
Next, we’ll clone the GitHub repo to get the example config and datasets:
cd C:\Users\anita\Documents\GitHub\ git clone https://github.com/geopython/pygeoapi.git cd pygeoapi\
To finish the setup, we need some configurations:
cp pygeoapi-config.yml example-config.yml # There is a known issue in pygeoapi 0.16.1: https://github.com/geopython/pygeoapi/issues/1597 # To fix it, edit the example-config.yml: uncomment the TinyDB option in the server settings (lines 51-54)
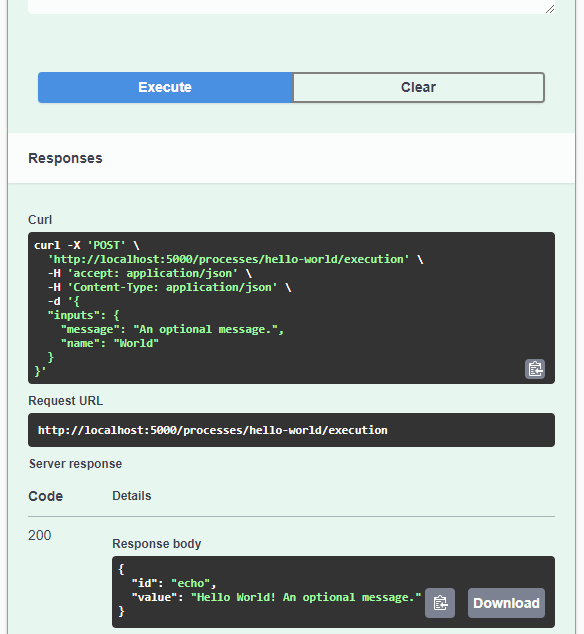
As you can see, writing JSON content for curl is a pain. Luckily, pyopenapi comes with a nice web GUI, including Swagger UI for playing with all the functionality, including the hello-world process:
It’s not really a geospatial hello-world example, but it’s a first step.
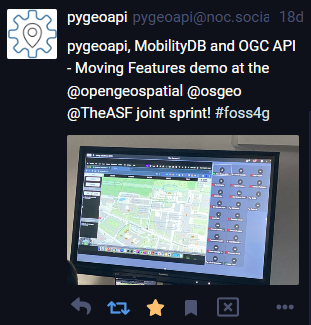
Finally, I wan’t to leave you with a teaser since there are more interesting things going on in this space, including work on OGC API – Moving Features as shared by the pygeoapi team recently:
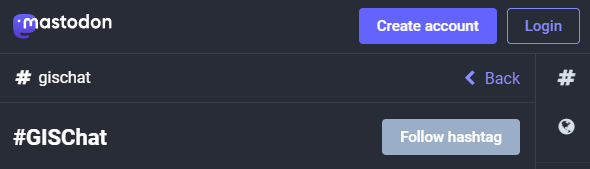
Besides following hashtags, such as #GISChat, #QGIS, #OpenStreetMap, #FOSS4G, and #OSGeo, curating good lists is probably the best way to stay up to date with geospatial developments.
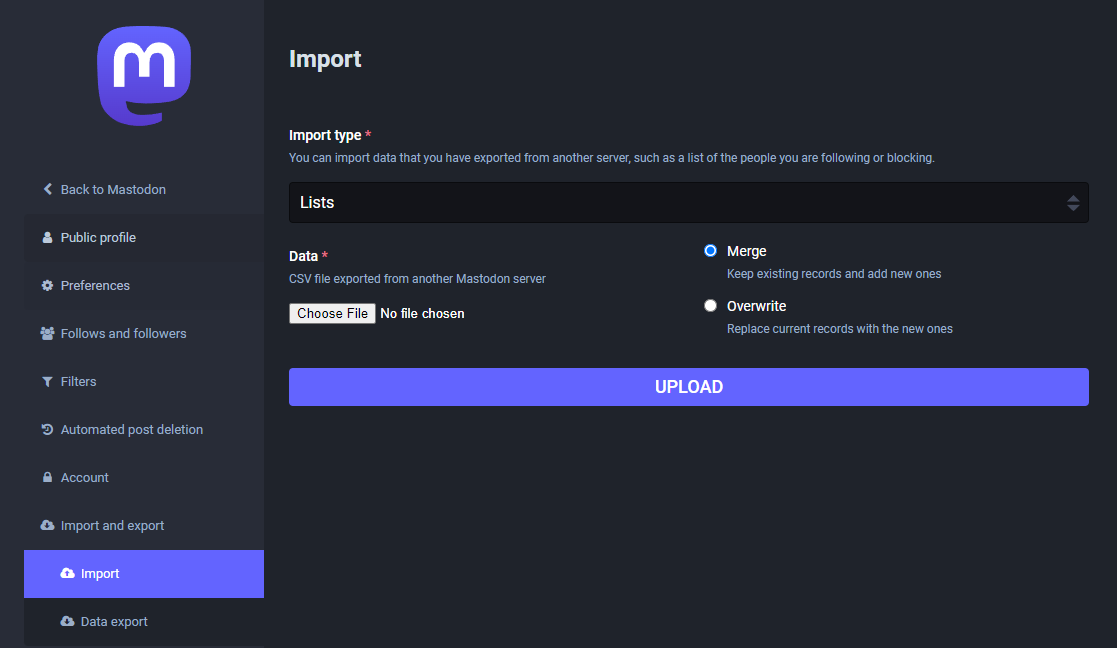
To get you started (or to potentially enrich your existing lists), I thought I’d share my Geospatial and SpatialDataScience lists with you. And the best thing: you don’t need to go through all the >150 entries manually! Instead, go to your Mastodon account settings and under “Import and export” you’ll find a tool to import and merge my list.csv with your lists:
And if you are not following the geospatial hashtags yet, you can search or click on the hashtags you’re interested in and start following to get all tagged posts into your timeline:
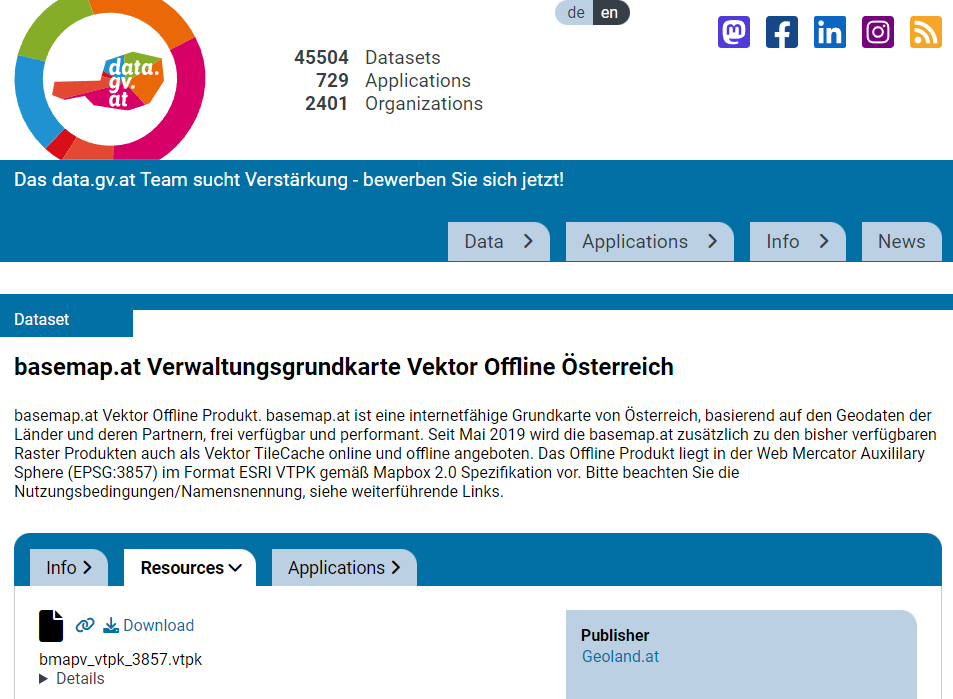
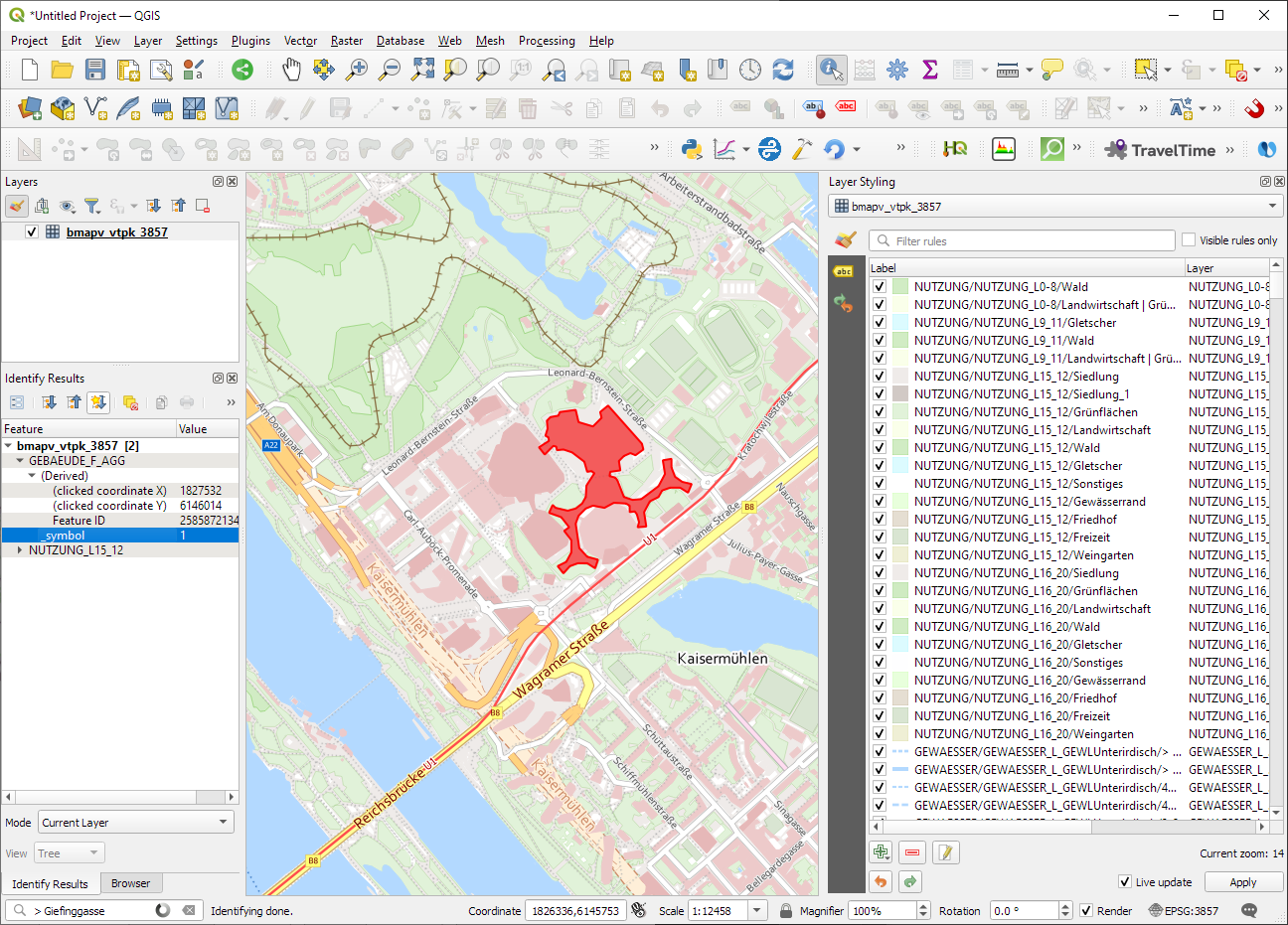
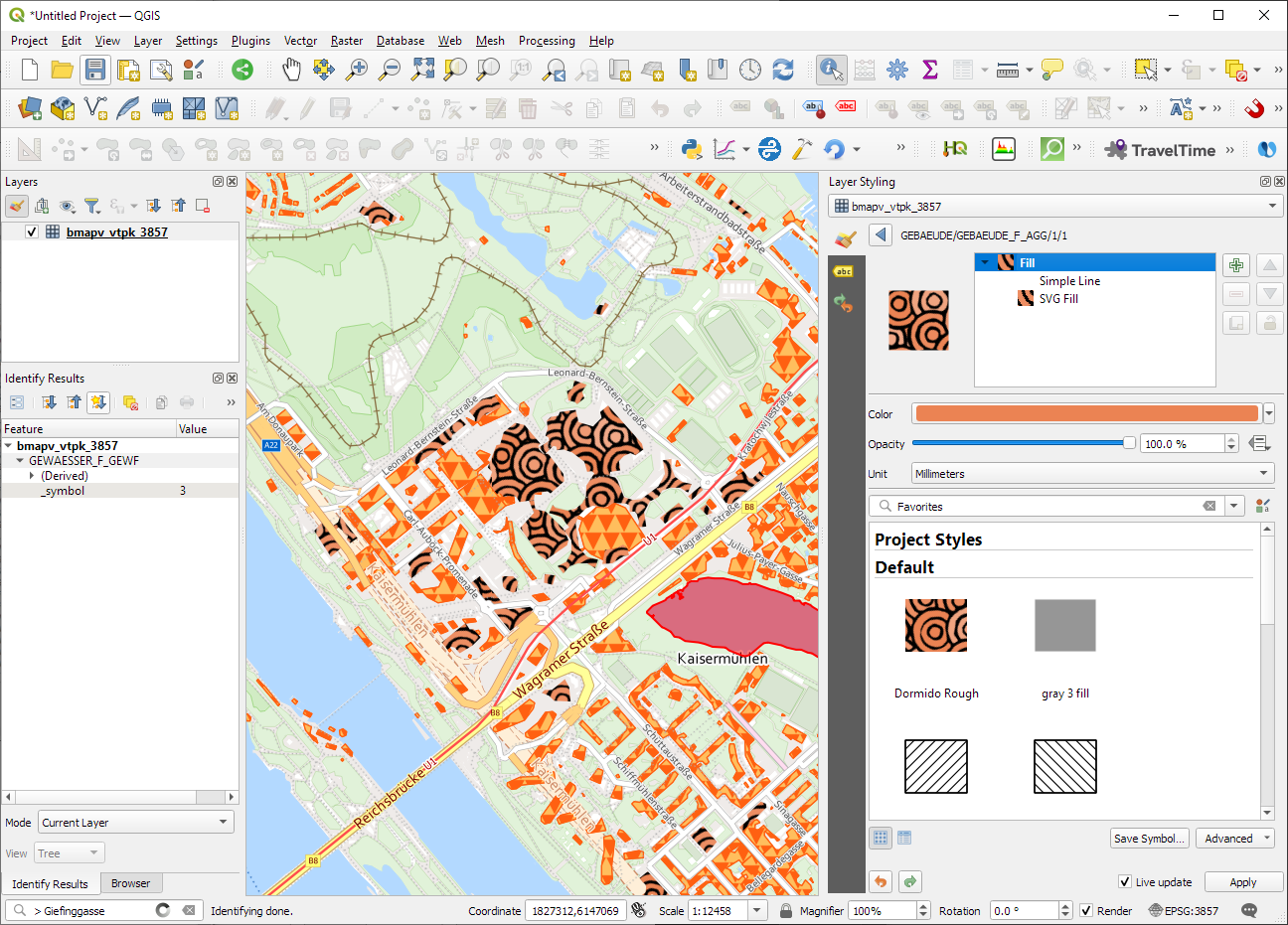
ESRI vector tile packages (VTPK files) can now be opened directly as vector tile layers via drag and drop, including support for style translation.
This is great news, particularly for users from Austria, since this makes it possible to use the open government basemap.at vector tiles directly, without any fuss:
In this post, Jakub Nowosad introduces our book “Geocomputation with Python”, also known as geocompy. It is an open-source book on geographic data analysis with Python, written by Michael Dorman, Jakub Nowosad, Robin Lovelace, and me with contributions from others. You can find it online at https://py.geocompx.org/
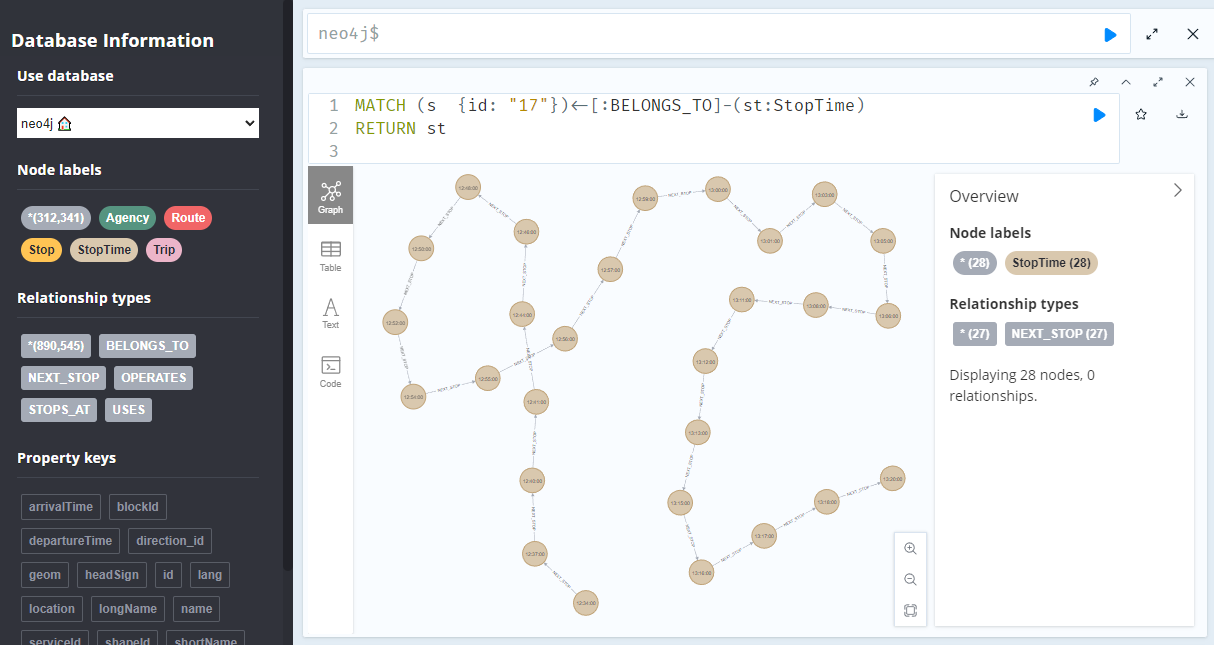
A prime example, are the relationships between GTFS StopTime and Trip nodes. For example, this is the Cypher query to get all StopTime nodes of Trip 17:
MATCH
(t:Trip {id: "17"})
<-[:BELONGS_TO]-
(st:StopTime)
RETURN st
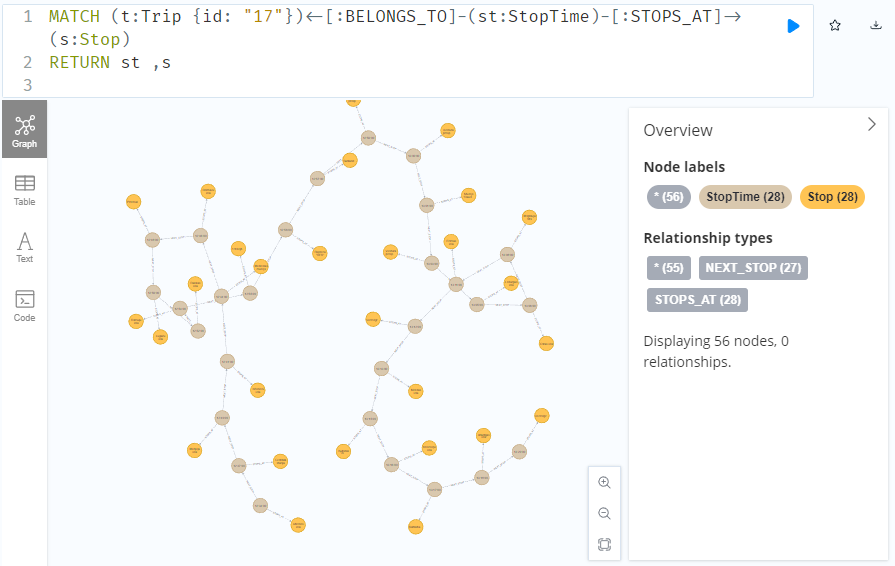
To get the stop locations, we also need to get the stop nodes:
MATCH
(t:Trip {id: "17"})
<-[:BELONGS_TO]-
(st:StopTime)
-[:STOPS_AT]->
(s:Stop)
RETURN st ,s
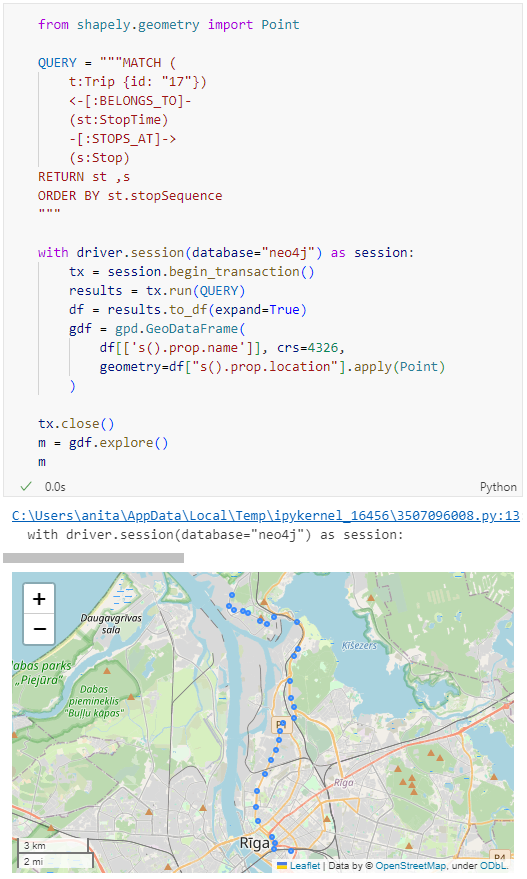
Adapting our code from the previous post, we can plot the stops:
from shapely.geometry import Point
QUERY = """MATCH (
t:Trip {id: "17"})
<-[:BELONGS_TO]-
(st:StopTime)
-[:STOPS_AT]->
(s:Stop)
RETURN st ,s
ORDER BY st.stopSequence
"""
with driver.session(database="neo4j") as session:
tx = session.begin_transaction()
results = tx.run(QUERY)
df = results.to_df(expand=True)
gdf = gpd.GeoDataFrame(
df[['s().prop.name']], crs=4326,
geometry=df["s().prop.location"].apply(Point)
)
tx.close()
m = gdf.explore()
m
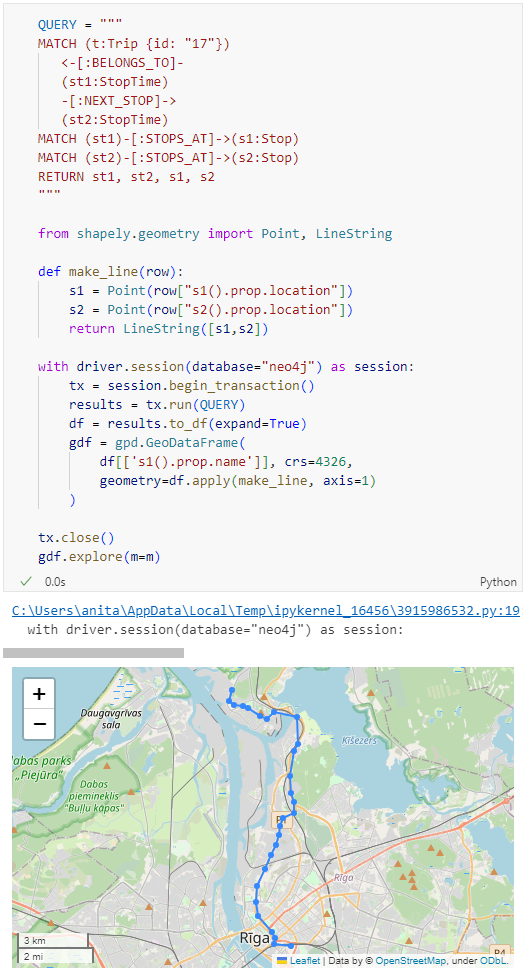
Ordering by stop sequence is actually completely optional. Technically, we could use the sorted GeoDataFrame, and aggregate all the points into a linestring to plot the route. But I want to try something different: we’ll use the NEXT_STOP relationships to get a DataFrame of the start and end stops for each segment:
QUERY = """
MATCH (t:Trip {id: "17"})
<-[:BELONGS_TO]-
(st1:StopTime)
-[:NEXT_STOP]->
(st2:StopTime)
MATCH (st1)-[:STOPS_AT]->(s1:Stop)
MATCH (st2)-[:STOPS_AT]->(s2:Stop)
RETURN st1, st2, s1, s2
"""
from shapely.geometry import Point, LineString
def make_line(row):
s1 = Point(row["s1().prop.location"])
s2 = Point(row["s2().prop.location"])
return LineString([s1,s2])
with driver.session(database="neo4j") as session:
tx = session.begin_transaction()
results = tx.run(QUERY)
df = results.to_df(expand=True)
gdf = gpd.GeoDataFrame(
df[['s1().prop.name']], crs=4326,
geometry=df.apply(make_line, axis=1)
)
tx.close()
gdf.explore(m=m)
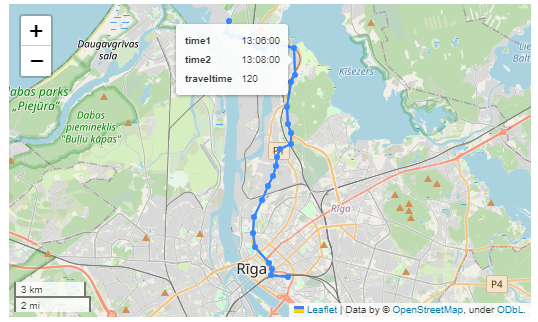
Finally, we can also use Cypher to calculate the travel time between two stops:
MATCH (t:Trip {id: "17"})
<-[:BELONGS_TO]-
(st1:StopTime)
-[:NEXT_STOP]->
(st2:StopTime)
MATCH (st1)-[:STOPS_AT]->(s1:Stop)
MATCH (st2)-[:STOPS_AT]->(s2:Stop)
RETURN st1.departureTime AS time1,
st2.arrivalTime AS time2,
s1.location AS geom1,
s2.location AS geom2,
duration.inSeconds(
time(st1.departureTime),
time(st2.arrivalTime)
).seconds AS traveltime
Then we can connect to our database. The default user name is neo4j and you get to pick the password when creating the database:
from neo4j import GraphDatabase
URI = "neo4j://localhost"
AUTH = ("neo4j", "password")
with GraphDatabase.driver(URI, auth=AUTH) as driver:
driver.verify_connectivity()
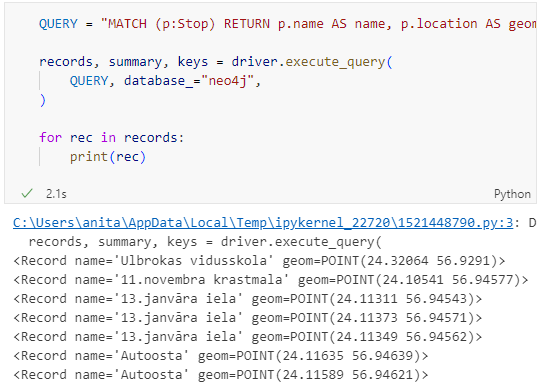
Once we have confirmed that the connection works as expected, we can run a query:
QUERY = "MATCH (p:Stop) RETURN p.name AS name, p.location AS geom"
records, summary, keys = driver.execute_query(
QUERY, database_="neo4j",
)
for rec in records:
print(rec)
Nice. There we have our GTFS stops, their names and their locations. But how to put them on a map?
import geopandas as gpd
import numpy as np
with driver.session(database="neo4j") as session:
tx = session.begin_transaction()
results = tx.run(QUERY)
df = results.to_df(expand=True)
df = df[df["geom[].0"]>0]
gdf = gpd.GeoDataFrame(
df['name'], crs=4326,
geometry=gpd.points_from_xy(df['geom[].0'], df['geom[].1']))
print(gdf)
tx.close()
Since some of the nodes lack geometries, I added a quick and dirty hack to get rid of these nodes because — otherwise — gdf.explore() will complain about None geometries.
In a recent post, we looked into a graph-based model for maritime mobility data and how it may be represented in Neo4J. Today, I want to look into another type of mobility data: public transport schedules in GTFS format.
Since a GTFS export is basically a ZIP archive full of CSVs, we will be making good use of Neo4Js CSV loading capabilities. The basic script for importing the stops file and creating point geometries from lat and lon values would be:
LOAD CSV with headers
FROM "file:///stops.txt"
AS row
CREATE (:Stop {
stop_id: row["stop_id"],
name: row["stop_name"],
location: point({
longitude: toFloat(row["stop_lon"]),
latitude: toFloat(row["stop_lat"])
})
})
This requires that the stops.txt is located in the import directory of your Neo4J database. When we run the above script and the file is missing, Neo4J will tell us where it tried to look for it. In my case, the directory ended up being:
So, let’s put all GTFS CSVs into that directory and we should be good to go.
Let’s start with the agency file:
load csv with headers from
'file:///agency.txt' as row
create (a:Agency {
id: row.agency_id,
name: row.agency_name,
url: row.agency_url,
timezone: row.agency_timezone,
lang: row.agency_lang
});
… Added 1 label, created 1 node, set 5 properties, completed after 31 ms.
The routes file does not include agency info but, luckily, there is only one agency, so we can hard-code it:
load csv with headers from
'file:///routes.txt' as row
match (a:Agency {id: "rigassatiksme"})
create (a)-[:OPERATES]->(r:Route {
id: row.route_id,
shortName: row.route_short_name,
longName: row.route_long_name,
type: toInteger(row.route_type)
});
… Added 81 labels, created 81 nodes, set 324 properties, created 81 relationships, completed after 28 ms.
From stops, I’m removing non-existent or empty columns:
load csv with headers from
'file:///stops.txt' as row
create (s:Stop {
id: row.stop_id,
name: row.stop_name,
location: point({
latitude: toFloat(row.stop_lat),
longitude: toFloat(row.stop_lon)
}),
code: row.stop_code
});
… Added 1671 labels, created 1671 nodes, set 5013 properties, completed after 71 ms.
From trips, I’m also removing non-existent or empty columns:
load csv with headers from
'file:///trips.txt' as row
match (r:Route {id: row.route_id})
create (r)<-[:USES]-(t:Trip {
id: row.trip_id,
serviceId: row.service_id,
headSign: row.trip_headsign,
direction_id: toInteger(row.direction_id),
blockId: row.block_id,
shapeId: row.shape_id
});
… Added 14427 labels, created 14427 nodes, set 86562 properties, created 14427 relationships, completed after 875 ms.
Slowly getting there. We now have around 16k nodes in our graph:
Finally, it’s stop times time. This is where the serious information is. This file is much larger than all previous ones with over 300k lines (i.e. times when an PT vehicle stops).
:auto
load csv with headers from
'file:///stop_times.txt' as row
CALL { with row
match (t:Trip {id: row.trip_id}), (s:Stop {id: row.stop_id})
create (t)<-[:BELONGS_TO]-(st:StopTime {
arrivalTime: row.arrival_time,
departureTime: row.departure_time,
stopSequence: toInteger(row.stop_sequence)})-[:STOPS_AT]->(s)
} IN TRANSACTIONS OF 10 ROWS;
… Added 351388 labels, created 351388 nodes, set 1054164 properties, created 702776 relationships, completed after 1364220 ms.
As you can see, this took a while. But now we have all nodes in place:
The final statement adds additional relationships between consecutive stop times:
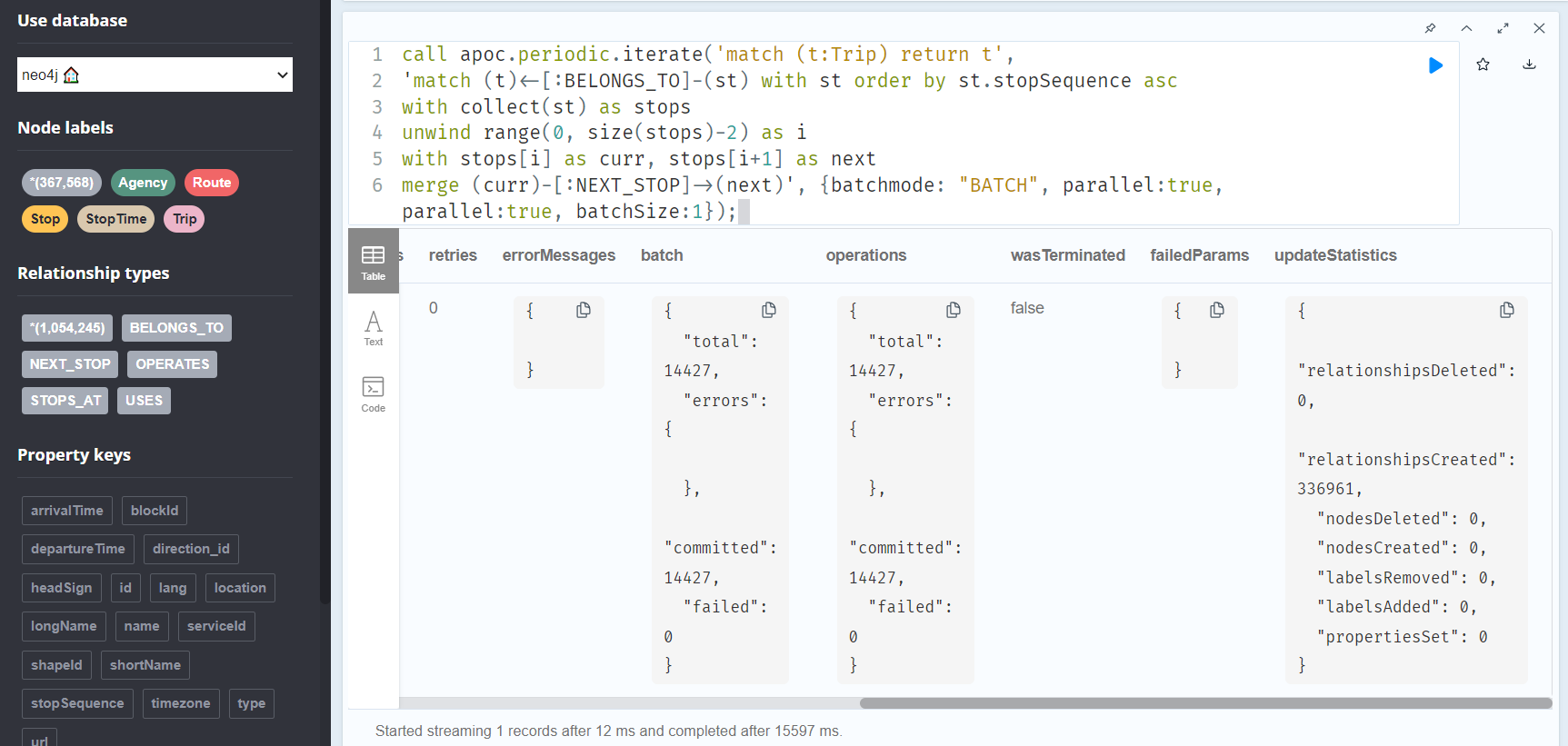
call apoc.periodic.iterate('match (t:Trip) return t',
'match (t)<-[:BELONGS_TO]-(st) with st order by st.stopSequence asc
with collect(st) as stops
unwind range(0, size(stops)-2) as i
with stops[i] as curr, stops[i+1] as next
merge (curr)-[:NEXT_STOP]->(next)', {batchmode: "BATCH", parallel:true, parallel:true, batchSize:1});
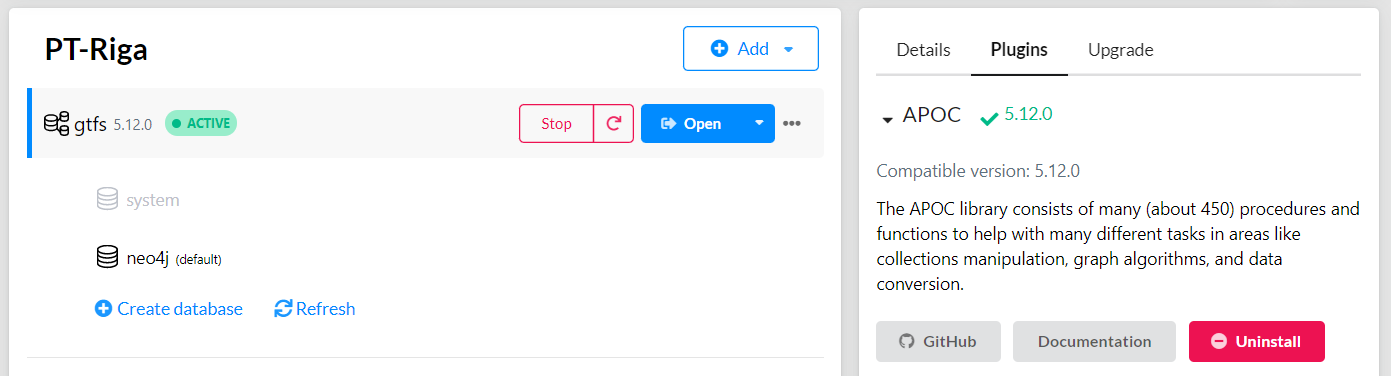
This fails with: There is no procedure with the name apoc.periodic.iterate registered for this database instance. Please ensure you've spelled the procedure name correctly and that the procedure is properly deployed.
So, let’s install APOC. That’s a plugin which we can install into our database from within Neo4J Desktop:
After restarting the db, we can run the query:
No errors. Sounds good.
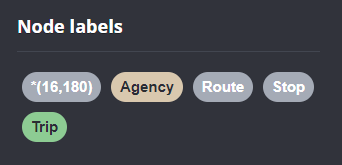
Let’s have a look at what we ended up with. Here are 25 random Trips. I expanded one of them to show its associated StopTimes. We can see the relations between consecutive StopTimes and I’ve expanded the final five StopTimes to show their linked Stops:
I also wanted to visualize the stops on a map. And there used to be a neat app called Neomap which can be installed easily:
Earlier this year, we explored how to use PyQGIS in Juypter notebooks to run QGIS Processing tools from a notebook and visualize the Processing results using GeoPandas plots.
Today, we’ll go a step further and replace the GeoPandas plots with maps rendered by QGIS.
The following script presents a minimum solution to this challenge: initializing a QGIS application, canvas, and project; then loading a GeoJSON and displaying it:
from IPython.display import Image
from PyQt5.QtGui import QColor
from PyQt5.QtWidgets import QApplication
from qgis.core import QgsApplication, QgsVectorLayer, QgsProject, QgsSymbol, \
QgsRendererRange, QgsGraduatedSymbolRenderer, \
QgsArrowSymbolLayer, QgsLineSymbol, QgsSingleSymbolRenderer, \
QgsSymbolLayer, QgsProperty
from qgis.gui import QgsMapCanvas
app = QApplication([])
qgs = QgsApplication([], False)
canvas = QgsMapCanvas()
project = QgsProject.instance()
vlayer = QgsVectorLayer("./data/traj.geojson", "My trajectory")
if not vlayer.isValid():
print("Layer failed to load!")
def saveImage(path, show=True):
canvas.saveAsImage(path)
if show: return Image(path)
project.addMapLayer(vlayer)
canvas.setExtent(vlayer.extent())
canvas.setLayers([vlayer])
canvas.show()
app.exec_()
saveImage("my-traj.png")
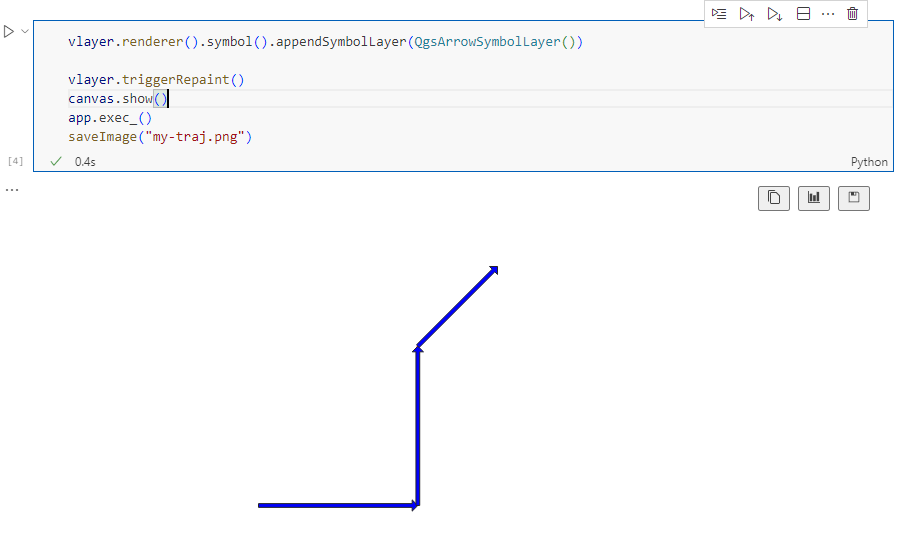
When this code is executed, it opens a separate window that displays the map canvas. And in this window, we can even pan and zoom to adjust the map. The line color, however, is assigned randomly (like when we open a new layer in QGIS):
Today’s post is a first quick dive into Neo4J (really just getting my toes wet). It’s based on a publicly available Neo4J dump containing mobility data, ship trajectories to be specific. You can find this data and the setup instructions at:
I was made aware of this work since they cited MovingPandas in their paper in Data & Knowledge Engineering: “The implementation combines several open source tools such as Python, MovingPandas library, Uber H3 index, Neo4j graph database management system”
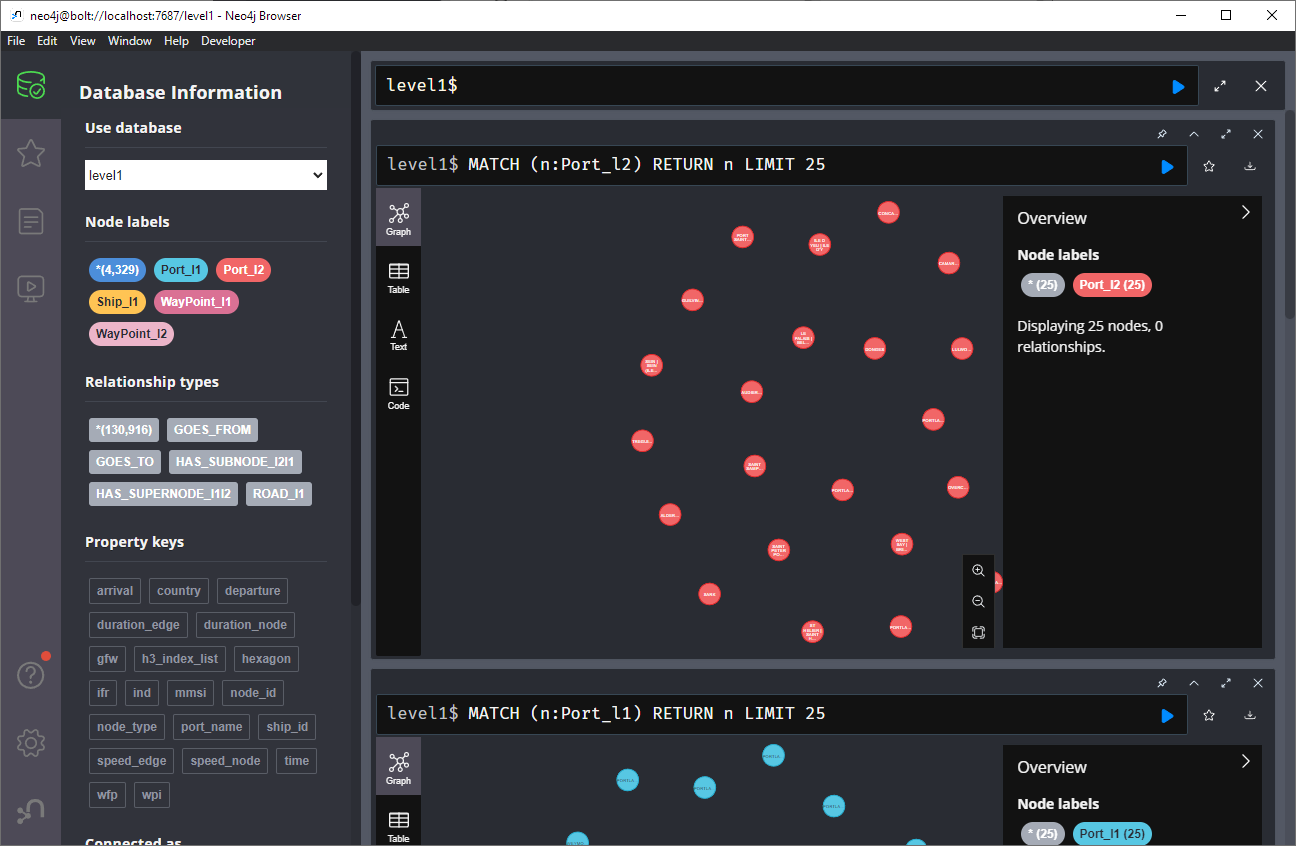
Once set up, this gives us a database with three hierarchical levels:
Neo4j comes with a nice graphical browser that lets us explore the data. We can switch between levels and click on individual node labels to get a quick preview:
Level 2 is a generalization / aggregation of level 1. Expanding the graph of one of the level 2 nodes shows its connection to level 1. For example, the level 2 port node “Audierne” actually refers to two level 1 nodes:
Every “road” level 1 relationship between ports provide information about the ship, its arrival, departure, travel time, and speed. We can see that this two level 1 ports must be pretty close since travel times are only 5 minutes:
Further expanding one of the port level 1 nodes shows its connection to waypoints of level1:
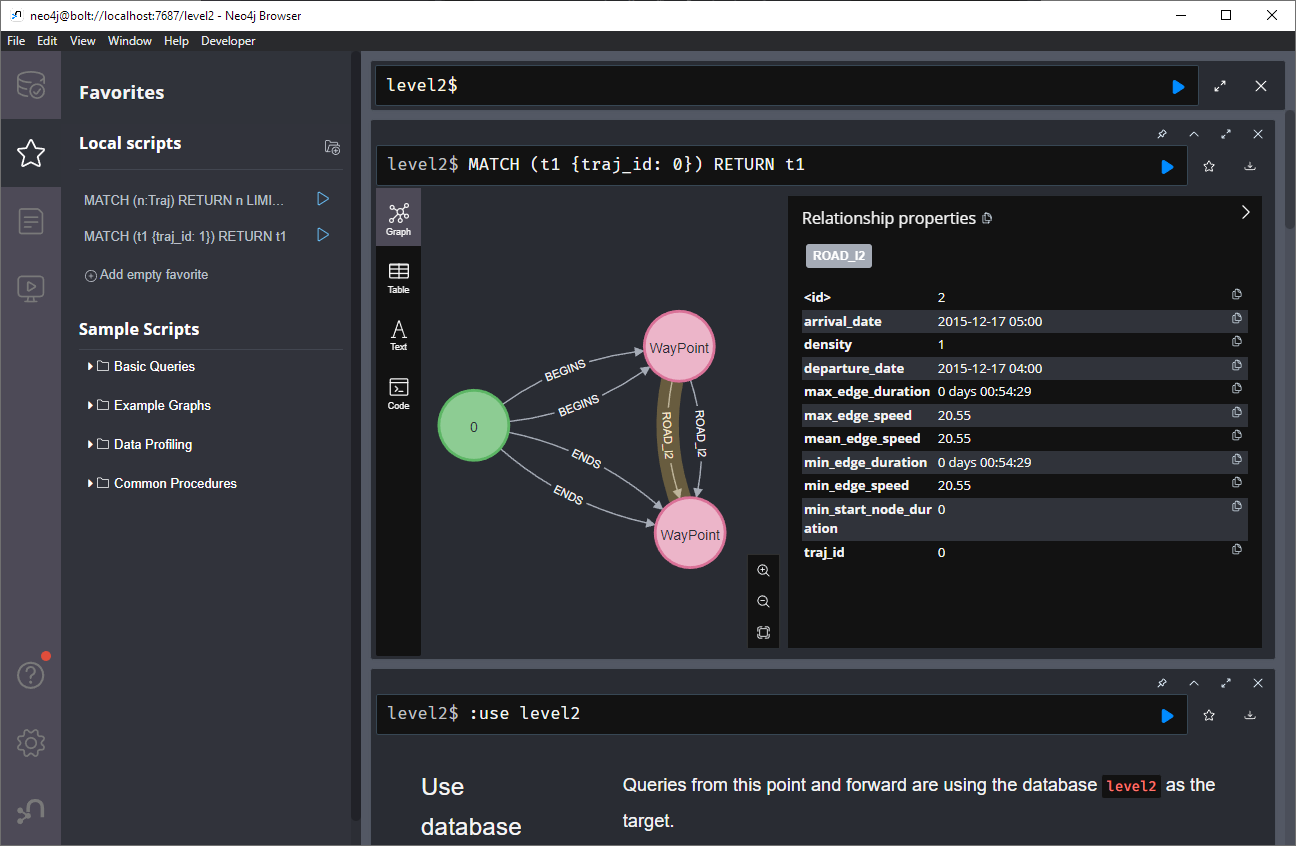
Switching to level 2, we gain access to nodes of type Traj(ectory). Additionally, the road level 2 relationships represent aggregations of the trajectories, for example, here’s a relationship with only one associated trajectory:
There are also some odd relationships, for example, trajectory 43 has two ends and begins relationships and there are also two road relationships referencing this trajectory (with identical information, only differing in their automatic <id>). I’m not yet sure if that is a feature or a bug:
On level 1, we also have access to ship nodes. They are connected to ports and waypoints. However, exploring them visually is challenging. Things look fine at first:
But after a while, once all relationships have loaded, we have it: the MIGHTY BALL OF YARN ™:
I guess this is the point where it becomes necessary to get accustomed to the query language. And no, it’s not SQL, it is Cypher. For example, selecting a specific trajectory with id 0, looks like this:
written together with my fellow “Geocomputation with Python” co-authors Robin Lovelace, Michael Dorman, and Jakub Nowosad.
In this blog post, we talk about our experience teaching R and Python for geocomputation. The context of this blog post is the OpenGeoHub Summer School 2023 which has courses on R, Python and Julia. The focus of the blog post is on geographic vector data, meaning points, lines, polygons (and their ‘multi’ variants) and the attributes associated with them. We plan to cover raster data in a future post.
Since I’ve been on Twitter since 2011, this means that some media files are now lost. While the loss of a few low-res images is probably not a major loss for humanity, I would prefer to have some control over when and how content I created vanishes. So, to avoid losing more content, I have followed Jeff’s recommendation to create a proper archival page:
It is based on an export I pulled in October 2022 when I started to use Mastodon as my primary social media account. Unfortunately, this export did not include media files.
Kaggle’s “Taxi Trajectory Data from ECML/PKDD 15: Taxi Trip Time Prediction (II) Competition” is one of the most used mobility / vehicle trajectory datasets in computer science. However, in contrast to other similar datasets, Kaggle’s taxi trajectories are provided in a format that is not readily usable in MovingPandas since the spatiotemporal information is provided as:
TIMESTAMP: (integer) Unix Timestamp (in seconds). It identifies the trip’s start;
POLYLINE: (String): It contains a list of GPS coordinates (i.e. WGS84 format) mapped as a string. The beginning and the end of the string are identified with brackets (i.e. [ and ], respectively). Each pair of coordinates is also identified by the same brackets as [LONGITUDE, LATITUDE]. This list contains one pair of coordinates for each 15 seconds of trip. The last list item corresponds to the trip’s destination while the first one represents its start;
Therefore, we need to create a DataFrame with one point + timestamp per row before we can use MovingPandas to create Trajectories and analyze them.
But first things first. Let’s download the dataset:
import datetime
import pandas as pd
import geopandas as gpd
import movingpandas as mpd
import opendatasets as od
from os.path import exists
from shapely.geometry import Point
input_file_path = 'taxi-trajectory/train.csv'
def get_porto_taxi_from_kaggle():
if not exists(input_file_path):
od.download("https://www.kaggle.com/datasets/crailtap/taxi-trajectory")
get_porto_taxi_from_kaggle()
df = pd.read_csv(input_file_path, nrows=10, usecols=['TRIP_ID', 'TAXI_ID', 'TIMESTAMP', 'MISSING_DATA', 'POLYLINE'])
df.POLYLINE = df.POLYLINE.apply(eval) # string to list
df
And now for the remodelling:
def unixtime_to_datetime(unix_time):
return datetime.datetime.fromtimestamp(unix_time)
def compute_datetime(row):
unix_time = row['TIMESTAMP']
offset = row['running_number'] * datetime.timedelta(seconds=15)
return unixtime_to_datetime(unix_time) + offset
def create_point(xy):
try:
return Point(xy)
except TypeError: # when there are nan values in the input data
return None
new_df = df.explode('POLYLINE')
new_df['geometry'] = new_df['POLYLINE'].apply(create_point)
new_df['running_number'] = new_df.groupby('TRIP_ID').cumcount()
new_df['datetime'] = new_df.apply(compute_datetime, axis=1)
new_df.drop(columns=['POLYLINE', 'TIMESTAMP', 'running_number'], inplace=True)
new_df
And that’s it. Now we can create the trajectories:
That’s it. Now our MovingPandas.TrajectoryCollection is ready for further analysis.
By the way, the plot above illustrates a new feature in the recent MovingPandas 0.16 release which, among other features, introduced plots with arrow markers that show the movement direction. Other new features include a completely new custom distance, speed, and acceleration unit support. This means that, for example, instead of always getting speed in meters per second, you can now specify your desired output units, including km/h, mph, or nm/h (knots).
I’ve previously written about Movement data in GIS and the AI hype and today’s post is a follow-up in which I want to share with you a new review of the state of the art in deep learning from trajectory data.
Our review covers 8 use cases:
Location classification
Arrival time prediction
Traffic flow / activity prediction
Trajectory prediction
Trajectory classification
Next location prediction
Anomaly detection
Synthetic data generation
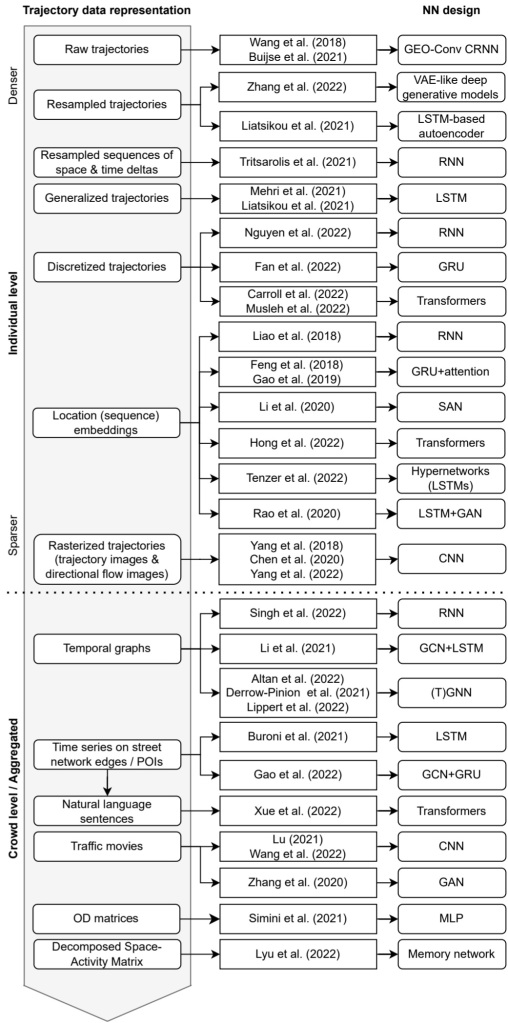
We particularly looked into the trajectory data preprocessing steps and the specific movement data representation used as input to train the neutral networks:
On a completely subjective note: the price for most surprising approach goes to natural language processing (NLP) Transfomers for traffic volume prediction.
The paper was presented at BMDA2023 and you can watch the full talk recording here:
DVC tracks data, parameters, and code. If anything changes, we simply rerun the process and DVC will figure out which stages need to be recomputed and which can be skipped by re-using cached results.
This can lead to huge time savings compared to re-running the whole model
I’m using DVC with the DVC plugin for VSCode but DVC can be used completely from the command line, if you prefer this appraoch.
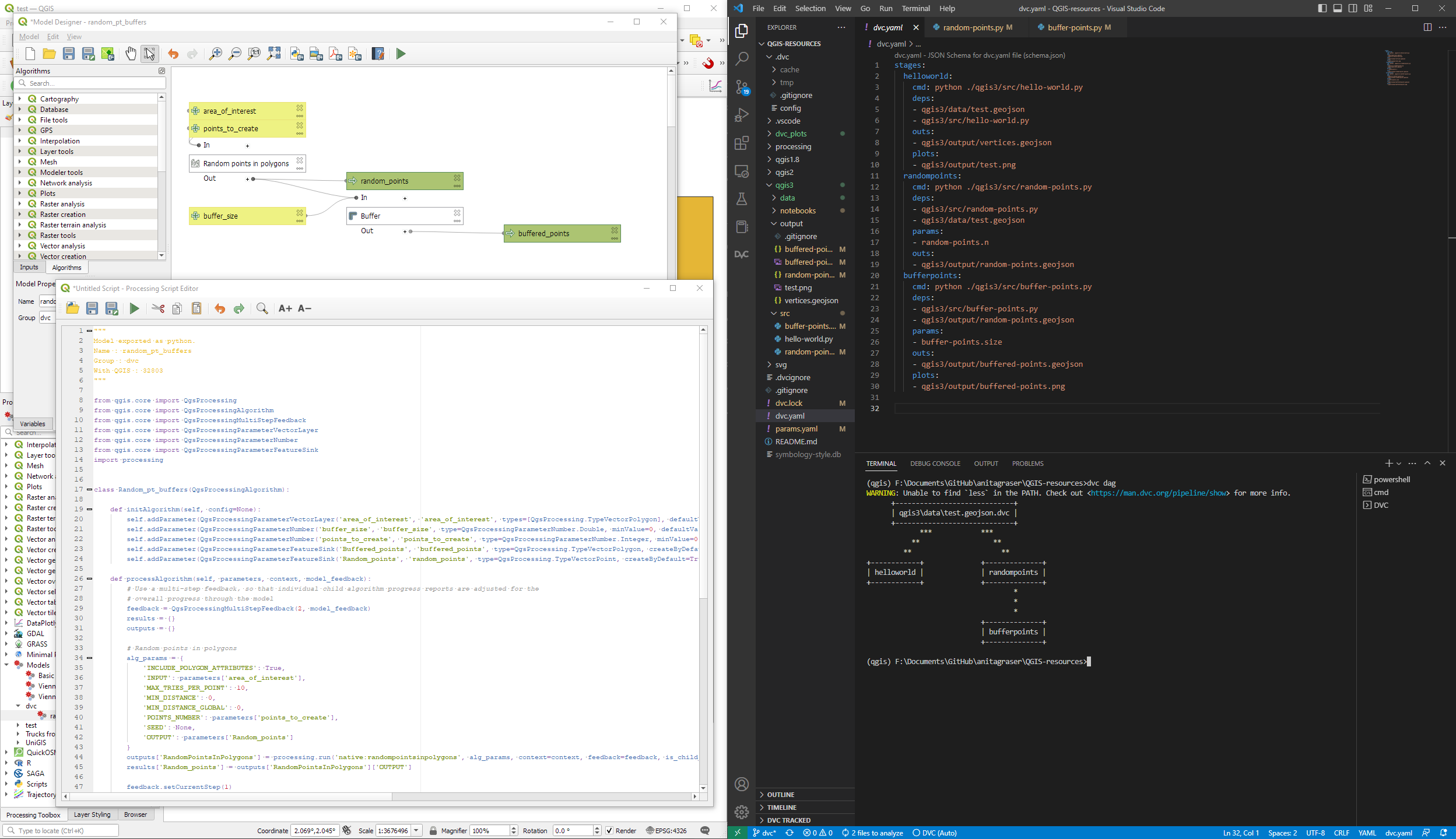
Basically, what follows is a proof of concept: converting a QGIS Processing model to a DVC workflow. In the following screenshot, you can see the main stages
The QGIS model in the upper left corner
The Python script exported from the QGIS model builder in the lower left corner
The DVC stages in my dvc.yaml file in the upper right corner (And please ignore the hello world stage. It’s a left over from my first experiment)
The DVC DAG visualizing the sequence of stages. Looks similar to the QGIS model, doesn’t it ;-)
Besides the stage definitions in dvc.yaml, there’s a parameters file:
random-points:
n: 10
buffer-points:
size: 0.5
And, of course, the two stages, each as it’s own Python script.
First, random-points.py which reads the random-points.n parameter to create the desired number of points within the polygon defined in qgis3/data/test.geojson:
With these things in place, we can use dvc to run the workflow, either from within VSCode or from the command line. Here, you can see the workflow (and how dvc skips stages and fetches results from cache) in action:
If you try it out yourself, let me know what you think.
In the previous post, we — creatively ;-) — used MobilityDB to visualize stationary IOT sensor measurements.
This post covers the more obvious use case of visualizing trajectories. Thus bringing together the MobilityDB trajectories created in Detecting close encounters using MobilityDB 1.0 and visualization using Temporal Controller.
Like in the previous post, the valueAtTimestamp function does the heavy lifting. This time, we also apply it to the geometry time series column called trip:
Today’s post presents an experiment in modelling a common scenario in many IOT setups: time series of measurements at stationary sensors. The key idea I want to explore is to use MobilityDB’s temporal data types, in particular the tfloat_inst and tfloat_seq for instances and sequences of temporal float values, respectively.
For info on how to set up MobilityDB, please check my previous post.
Setting up our DB tables
As a toy example, let’s create two IOT devices (in table iot_devices) with three measurements each (in table iot_measurements) and join them to create the tfloat_seq (in table iot_joined):
CREATE TABLE iot_devices (
id integer,
geom geometry(Point, 4326)
);
INSERT INTO iot_devices (id, geom) VALUES
(1, ST_SetSRID(ST_MakePoint(1,1), 4326)),
(2, ST_SetSRID(ST_MakePoint(2,3), 4326));
CREATE TABLE iot_measurements (
device_id integer,
t timestamp,
measurement float
);
INSERT INTO iot_measurements (device_id, t, measurement) VALUES
(1, '2022-10-01 12:00:00', 5.0),
(1, '2022-10-01 12:01:00', 6.0),
(1, '2022-10-01 12:02:00', 10.0),
(2, '2022-10-01 12:00:00', 9.0),
(2, '2022-10-01 12:01:00', 6.0),
(2, '2022-10-01 12:02:00', 1.5);
CREATE TABLE iot_joined AS
SELECT
dev.id,
dev.geom,
tfloat_seq(array_agg(
tfloat_inst(m.measurement, m.t) ORDER BY t
)) measurements
FROM iot_devices dev
JOIN iot_measurements m
ON dev.id = m.device_id
GROUP BY dev.id, dev.geom;
We can load the resulting layer in QGIS but QGIS won’t be happy about the measurements column because it does not recognize its data type:
Query layer with valueAtTimestamp
Instead, what we can do is create a query layer that fetches the measurement value at a specific timestamp:
SELECT id, geom,
valueAtTimestamp(measurements, '2022-10-01 12:02:00')
FROM iot_joined
Which gives us a layer that QGIS is happy with:
Time for TemporalController
Now the tricky question is: how can we wire our query layer to the Temporal Controller so that we can control the timestamp and animate the layer?
I don’t have a GUI solution yet but here’s a way to do it with PyQGIS: whenever the Temporal Controller signal updateTemporalRange is emitted, our update_query_layer function gets the current time frame start time and replaces the datetime in the query layer’s data source with the current time:
l = iface.activeLayer()
tc = iface.mapCanvas().temporalController()
def update_query_layer():
tct = tc.dateTimeRangeForFrameNumber(tc.currentFrameNumber()).begin().toPyDateTime()
s = l.source()
new = re.sub(r"(\d{4})-(\d{2})-(\d{2}) (\d{2}):(\d{2}):(\d{2})", str(tct), s)
l.setDataSource(new, l.sourceName(), l.dataProvider().name())
tc.updateTemporalRange.connect(update_query_layer)
Future experiments will have to show how this approach performs on lager datasets but it’s exciting to see how MobilityDB’s temporal types may be visualized in QGIS without having to create tables/views that join a geometry to each and every individual measurement.
It’s been a while since we last talked about MobilityDB in 2019 and 2020. Since then, the project has come a long way. It joined OSGeo as a community project and formed a first PSC, including the project founders Mahmoud Sakr and Esteban Zimányi as well as Vicky Vergara (of pgRouting fame) and yours truly.
This post is a quick teaser tutorial from zero to computing closest points of approach (CPAs) between trajectories using MobilityDB.
Setting up MobilityDB with Docker
The easiest way to get started with MobilityDB is to use the ready-made Docker container provided by the project. I’m using Docker and WSL (Windows Subsystem Linux on Windows 10) here. Installing WLS/Docker is out of scope of this post. Please refer to the official documentation for your operating system.
Once Docker is ready, we can pull the official container and fire it up:
Currently, the container provides PostGIS 3.2 and MobilityDB 1.0:
Loading movement data into MobilityDB
Once the container is running, we can already connect to it from QGIS. This is my preferred way to load data into MobilityDB because we can simply drag-and-drop any timestamped point layer into the database:
For this post, I’m using an AIS data sample in the region of Gothenburg, Sweden.
After loading this data into a new table called ais, it is necessary to remove duplicate and convert timestamps:
CREATE TABLE AISInputFiltered AS
SELECT DISTINCT ON("MMSI","Timestamp") *
FROM ais;
ALTER TABLE AISInputFiltered ADD COLUMN t timestamp;
UPDATE AISInputFiltered SET t = "Timestamp"::timestamp;
Afterwards, we can create the MobilityDB trajectories:
CREATE TABLE Ships AS
SELECT "MMSI" mmsi,
tgeompoint_seq(array_agg(tgeompoint_inst(Geom, t) ORDER BY t)) AS Trip,
tfloat_seq(array_agg(tfloat_inst("SOG", t) ORDER BY t) FILTER (WHERE "SOG" IS NOT NULL) ) AS SOG,
tfloat_seq(array_agg(tfloat_inst("COG", t) ORDER BY t) FILTER (WHERE "COG" IS NOT NULL) ) AS COG
FROM AISInputFiltered
GROUP BY "MMSI";
ALTER TABLE Ships ADD COLUMN Traj geometry;
UPDATE Ships SET Traj = trajectory(Trip);
Once this is done, we can load the resulting Ships layer and the trajectories will be loaded as lines:
Computing closest points of approach
To compute the closest point of approach between two moving objects, MobilityDB provides a shortestLine function. To be correct, this function computes the line connecting the nearest approach point between the two tgeompoint_seq. In addition, we can use the time-weighted average function twavg to compute representative average movement speeds and eliminate stationary or very slowly moving objects:
SELECT S1.MMSI mmsi1, S2.MMSI mmsi2,
shortestLine(S1.trip, S2.trip) Approach,
ST_Length(shortestLine(S1.trip, S2.trip)) distance
FROM Ships S1, Ships S2
WHERE S1.MMSI > S2.MMSI AND
twavg(S1.SOG) > 1 AND twavg(S2.SOG) > 1 AND
dwithin(S1.trip, S2.trip, 0.003)
In the QGIS Browser panel, we can right-click the MobilityDB connection to bring up an SQL input using Execute SQL:
The resulting query layer shows where moving objects get close to each other:
To better see what’s going on, we’ll look at individual CPAs:
Having a closer look with the Temporal Controller
Since our filtered AIS layer has proper timestamps, we can animate it using the Temporal Controller. This enables us to replay the movement and see what was going on in a certain time frame.
I let the animation run and stopped it once I spotted a close encounter. Looking at the AIS points and the shortest line, we can see that MobilityDB computed the CPAs along the trajectories:
A more targeted way to investigate a specific CPA is to use the Temporal Controllers’ fixed temporal range mode to jump to a specific time frame. This is helpful if we already know the time frame we are interested in. For the CPA use case, this means that we can look up the timestamp of a nearby AIS position and set up the Temporal Controller accordingly:
More
I hope you enjoyed this quick dive into MobilityDB. For more details, including talks by the project founders, check out the project website.
















 ) since I
) since I