Introducing the open data analysis OGD.AT Lab
Data sourcing and preparation is one of the most time consuming tasks in many spatial analyses. Even though the Austrian data.gv.at platform already provides a central catalog, the individual datasets still vary considerably in their accessibility or readiness for use.
OGD.AT Lab is a new repository collecting Jupyter notebooks for working with Austrian Open Government Data and other auxiliary open data sources. The notebooks illustrate different use cases, including so far:
- Accessing geodata from the city of Vienna WFS
- Downloading environmental data (heat vulnerability and air quality)
- Geocoding addresses and getting elevation information
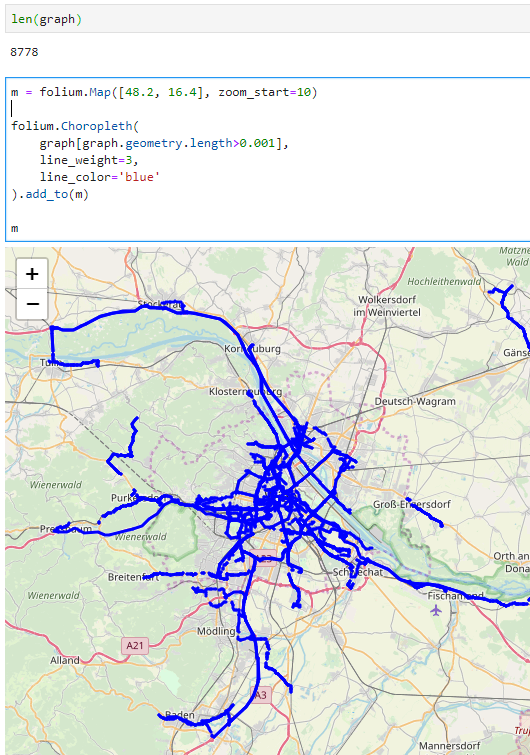
- Exploring urban movement data
Data processing and visualization are performed using Pandas, GeoPandas, and Holoviews. GeoPandas makes it straighforward to use data from WFS. Therefore, OGD.AT Lab can provide one universal gdf_from_wfs() function which takes the desired WFS layer as an argument and returns a GeoPandas.GeoDataFrame that is ready for analysis:

Launch this notebook in: https://mybinder.org/v2/gh/anitagraser/ogd-at-lab/v0.1?urlpath=lab/tree/notebooks/wien-ogd.ipynb
Many other datasets are provided as CSV files which need to be joined with spatial datasets to use them in spatial analysis. For example, the “Urban heat vulnerability index” dataset which needs to be joined to statistical areas.

Launch this notebook in Mybinder: https://mybinder.org/v2/gh/anitagraser/ogd-at-lab/v0.1?urlpath=lab/tree/notebooks/environment.ipynb
Another issue with many CSV files is that they use German number formatting, where commas are used as a decimal separater instead of dots:

Besides file access, there are also open services provided by other developers, for example, Manfred Egger developed an elevation service that provides elevation information for any point in Austria. In combination with geocoding services, such as Nominatim, this makes is possible to, for example, find the elevation for any address in Austria:

Launch this notebook in MyBinder: https://mybinder.org/v2/gh/anitagraser/ogd-at-lab/v0.1?urlpath=lab/tree/notebooks/elevation.ipynb
Last but not least, the first version of the mobility notebook showcases open travel time data provided by Uber Movement:

Launch this notebook in Mybinder: https://mybinder.org/v2/gh/anitagraser/ogd-at-lab/v0.1?urlpath=lab/tree/notebooks/mobility.ipynb
The utility functions for data access included in this repository will continue to grow as new data sources are included. Eventually, it may make sense to extract the data access function into a dedicated library, similar to geofi (Finland) or geobr (Brazil).
If you’re aware of any interesting open datasets or services that should be included in OGD.AT, feel free to reach out here or on Github through the issue tracker or by providing a pull request.
 Dash HoloViews was just released as part of
Dash HoloViews was just released as part of  Automatically link selections across multiple plots (crossfiltering)
Automatically link selections across multiple plots (crossfiltering)