Movement data in GIS #35: stop detection & analysis with MovingPandas
In the last few days, there’s been a sharp rise in interest in vessel movements, and particularly, in understanding where and why vessels stop. Following the grounding of Ever Given in the Suez Canal, satellite images and vessel tracking data (AIS) visualizations are everywhere:
Using movement data analytics tools, such as MovingPandas, we can dig deeper and explore patterns in the data.
The MovingPandas.TrajectoryStopDetector is particularly useful in this situation. We can provide it with a Trajectory or TrajectoryCollection and let it detect all stops, that is, instances were the moving object stayed within a certain area (with a diameter of 1000m in this example) for a an extended duration (at least 3 hours).
stops = mpd.TrajectoryStopDetector(trajs).get_stop_segments(
min_duration=timedelta(hours=3), max_diameter=1000)
The resulting stop segments include spatial and temporal information about the stop location and duration. To make this info more easily accessible, let’s turn the stop segment TrajectoryCollection into a point GeoDataFrame:
stop_pts = gpd.GeoDataFrame(columns=['geometry']).set_geometry('geometry')
stop_pts['stop_id'] = [track.id for track in stops.trajectories]
stop_pts= stop_pts.set_index('stop_id')
for stop in stops:
stop_pts.at[stop.id, 'ID'] = stop.df['ID'][0]
stop_pts.at[stop.id, 'datetime'] = stop.get_start_time()
stop_pts.at[stop.id, 'duration_h'] = stop.get_duration().total_seconds()/3600
stop_pts.at[stop.id, 'geometry'] = stop.get_start_location()
Indeed, I think the next version of MovingPandas should include a function that directly returns stops as points.
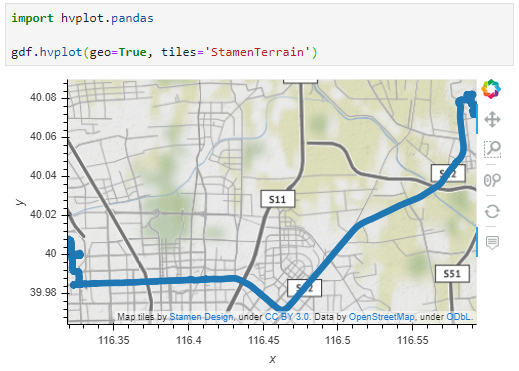
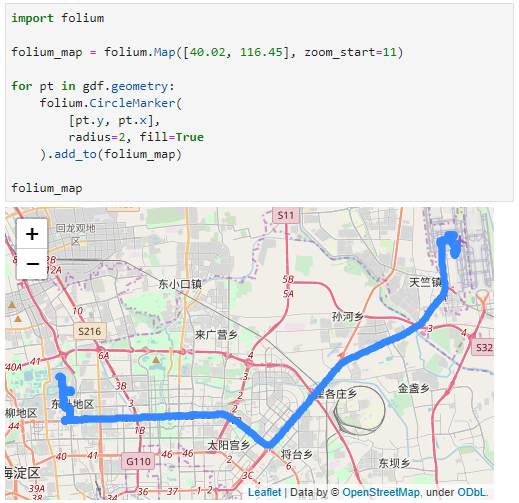
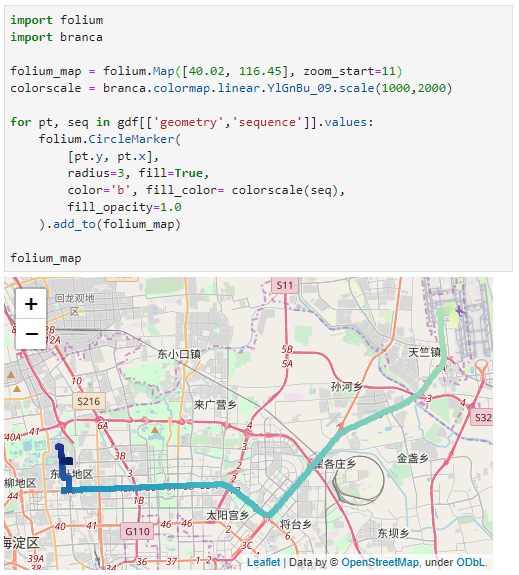
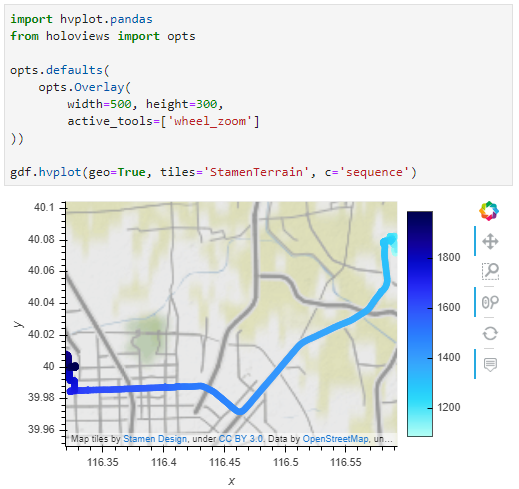
Now we can explore the stop information. For example, the map plot shows that stops are concentrated in three main areas: the northern and southern ends of the Canal, as well as the Great Bitter Lake in the middle. By looking at the timing of stops and their duration in a scatter plot, we can clearly see that the Ever Given stop (red) caused a chain reaction: the numerous points lining up on the diagonal of the scatter plot represent stops that very likely are results of the blockage:

Before the grounding, the stop distribution nicely illustrates the canal schedule. Vessels have to wait until it’s turn for their direction to go through:

You can see the full analysis workflow in the following video. Please turn on the captions for details.
Huge thanks to VesselsValue for supplying the data!
For another example of MovingPandas‘ stop dectection in action, have a look at Bryan R. Vallejo’s tutorial on detecting stops in bird tracking data which includes some awesome visualizations using KeplerGL:

This post is part of a series. Read more about movement data in GIS.



 Dash HoloViews was just released as part of
Dash HoloViews was just released as part of  Automatically link selections across multiple plots (crossfiltering)
Automatically link selections across multiple plots (crossfiltering)