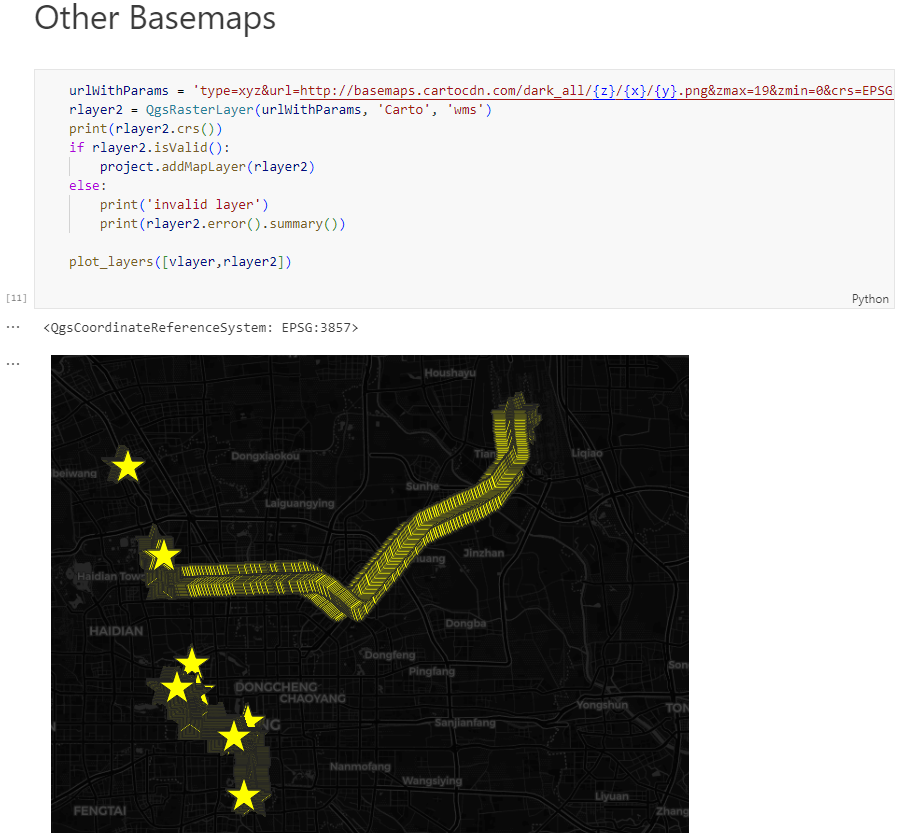
New MovingPandas tutorial: taking OGC Moving Features full circle with MF-JSON

Last week, I had the pleasure to meet some of the people behind the OGC Moving Features Standard Working group at the IEEE Mobile Data Management Conference (MDM2024). While chatting about the Moving Features (MF) support in MovingPandas, I realized that, after the MF-JSON update & tutorial with official sample post, we never published a complete tutorial on working with MF-JSON encoded data in MovingPandas.

The current MovingPandas development version (to be release as version 0.19) supports:
- Reading MF-JSON MovingPoint (single trajectory features and trajectory collections)
- Reading MF-JSON Trajectory
- Writing MovingPandas Trajectories and TrajectoryCollections to MF-JSON MovingPoint
This means that we can now go full circle: reading — writing — reading.
Reading MF-JSON
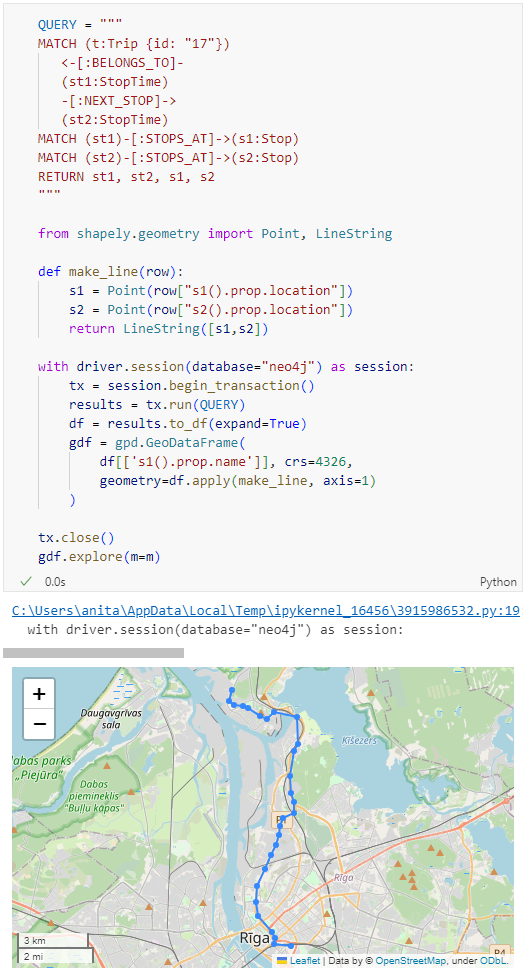
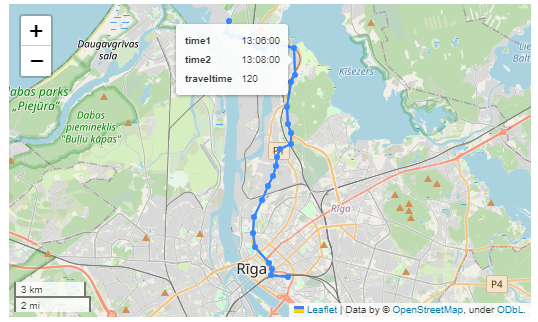
Both MF-JSON MovingPoint encoding and Trajectory encoding can be read using the MovingPandas function read_mf_json(). The complete Jupyter notebook for this tutorial is available in the project repo.
Here we read one of the official MF-JSON MovingPoint sample files:
traj = mpd.read_mf_json('data/movingfeatures.json')

Writing MF-JSON
To write MF-JSON, the Trajectory and TrajectoryCollection classes provide a to_mf_json() function:

The resulting Python dictionary in MF-JSON MovingPoint encoding can then be saved to a JSON file, and then read again:
import json
with open('mf1.json', 'w') as json_file:
json.dump(mf_json, json_file, indent=4)

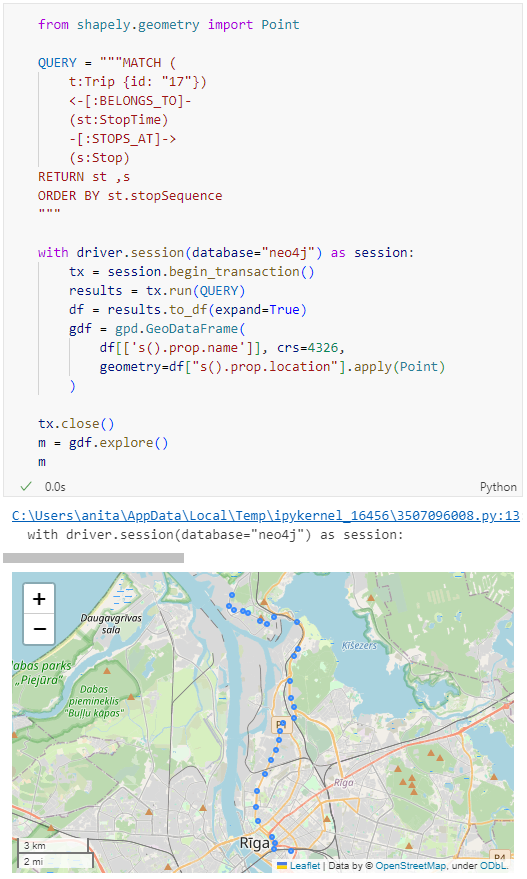
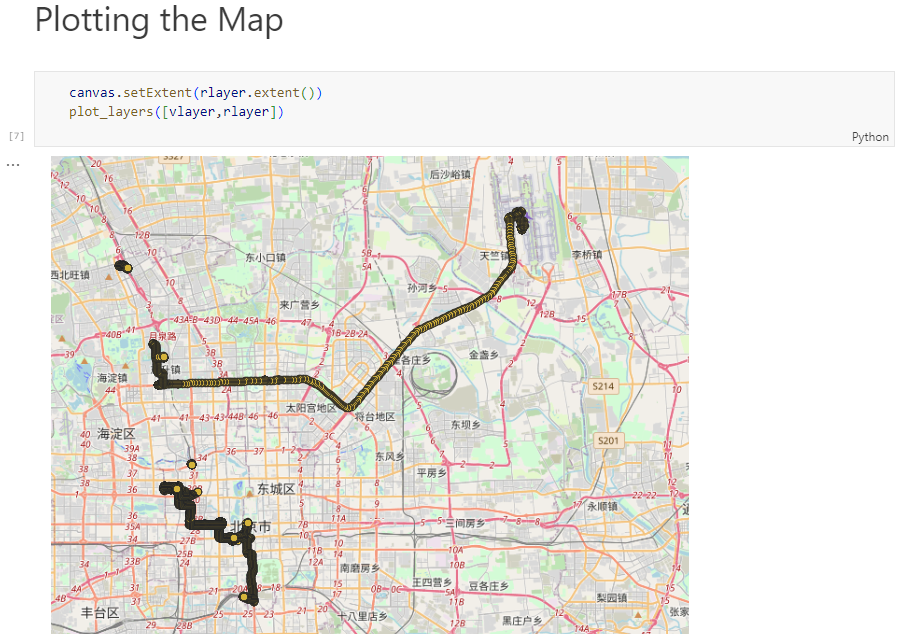
Similarly, we can read any arbitrary trajectory data set and save it to MF-JSON.
For example, here we use our usual Geolife sample:
gdf = gp.read_file('data/demodata_geolife.gpkg')
tc = mpd.TrajectoryCollection(gdf, 'trajectory_id', t='t')
mf_json = tc.to_mf_json(temporal_columns=['sequence'])

And reading again
import json
with open('mf5.json', 'w') as json_file:
json.dump(mf_json, json_file, indent=4)
tc = mpd.read_mf_json('mf5.json', traj_id_property='trajectory_id' )

Conclusion
The implemented MF-JSON support covers the basic usage of the encodings. There are some fine details in the standard, such as the distinction of time-varying attribute with linear versus step-wise interpolation, which MovingPandas currently does not support.
If you are working with movement data, I would appreciate if you can give the improved MF-JSON support a spin and report back with your experiences.