Movement data in GIS #34: a protocol for exploring movement data
After writing “Towards a template for exploring movement data” last year, I spent a lot of time thinking about how to develop a solid approach for movement data exploration that would help analysts and scientists to better understand their datasets. Finally, my search led me to the excellent paper “A protocol for data exploration to avoid common statistical problems” by Zuur et al. (2010). What they had done for the analysis of common ecological datasets was very close to what I was trying to achieve for movement data. I followed Zuur et al.’s approach of a exploratory data analysis (EDA) protocol and combined it with a typology of movement data quality problems building on Andrienko et al. (2016). Finally, I brought it all together in a Jupyter notebook implementation which you can now find on Github.
There are two options for running the notebook:
- The repo contains a Dockerfile you can use to spin up a container including all necessary datasets and a fitting Python environment.
- Alternatively, you can download the datasets manually and set up the Python environment using the provided environment.yml file.
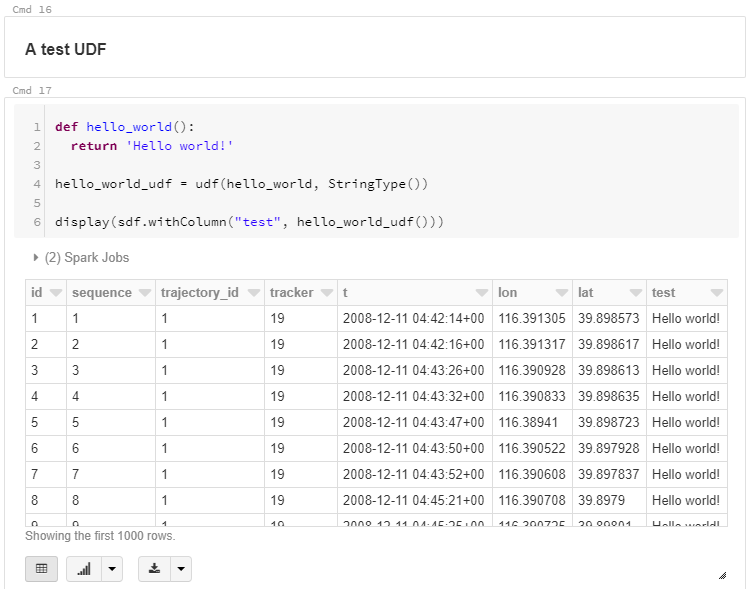
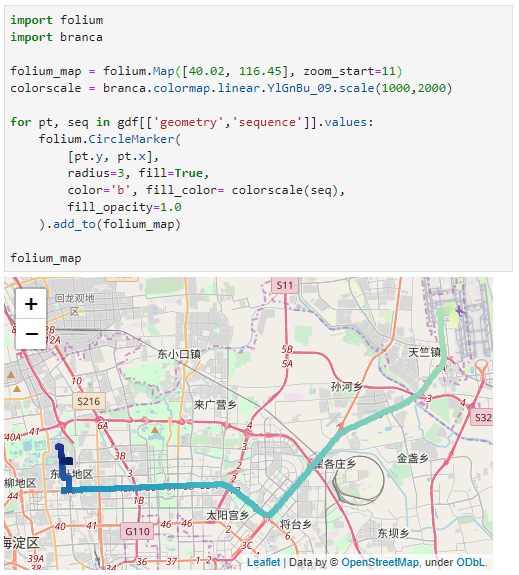
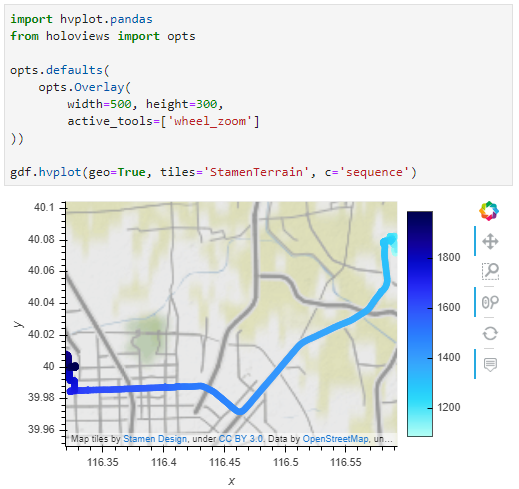
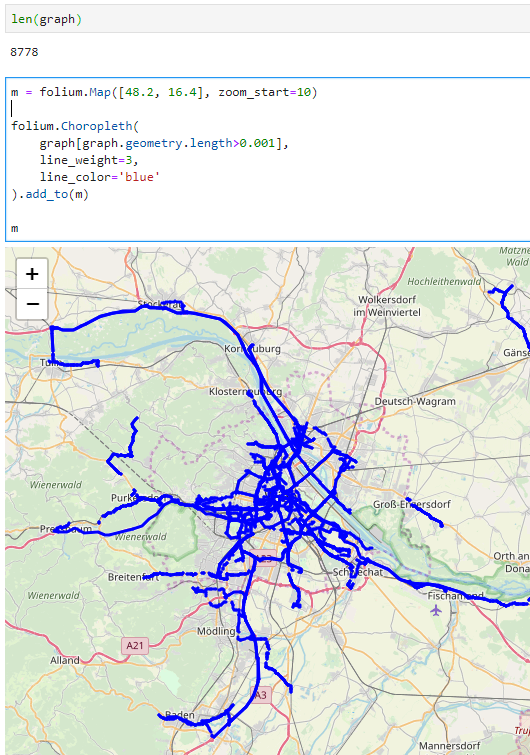
The dataset contains over 10 million location records. Most visualizations are based on Holoviz Datashader with a sprinkling of MovingPandas for visualizing individual trajectories.

Point density map of 10 million location records, visualized using Datashader

Line density map for detecting gaps in tracks, visualized using Datashader

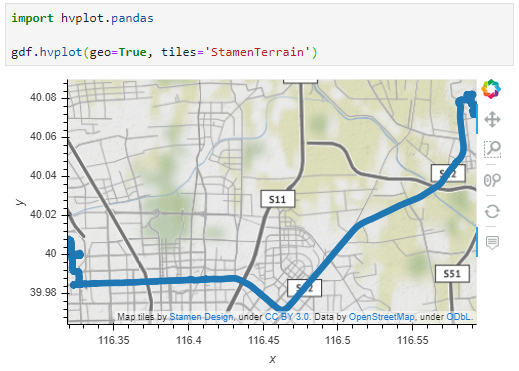
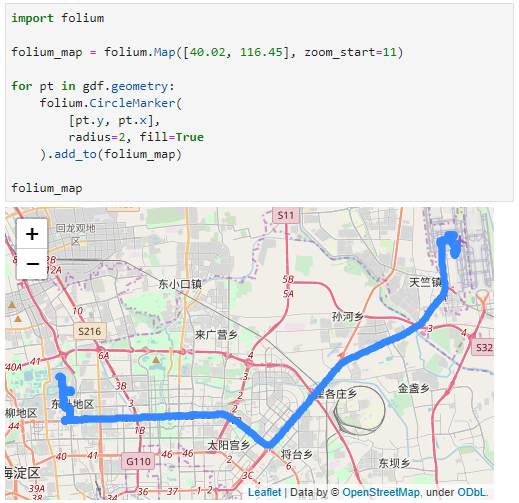
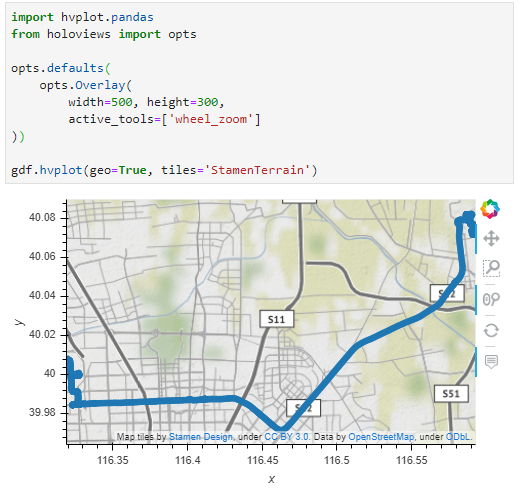
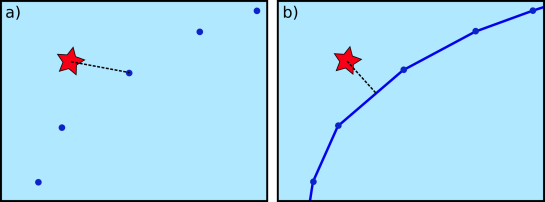
Example trajectory with strong jitter, visualized using MovingPandas & GeoViews
I hope this reference implementation will provide a starting point for many others who are working with movement data and who want to structure their data exploration workflow.
If you want to dive deeper, here’s the paper:
(If you don’t have institutional access to the journal, the publisher provides 50 free copies using this link. Once those are used up, just leave a comment below and I can email you a copy.)
References
- Zuur, A. F., Ieno, E. N., & Elphick, C. S. (2010). A protocol for data exploration to avoid common statistical problems. Methods in ecology and evolution, 1(1), 3-14. https://doi.org/10.1111/j.2041-210X.2009.00001.x.
- Andrienko, G., Andrienko, N., & Fuchs, G. (2016). Understanding movement data quality. Journal of location Based services, 10(1), 31-46. doi:10.1080/17489725.2016.1169322.
This post is part of a series. Read more about movement data in GIS.





 Dash HoloViews was just released as part of
Dash HoloViews was just released as part of  Automatically link selections across multiple plots (crossfiltering)
Automatically link selections across multiple plots (crossfiltering)