Movement data in GIS #23: trajectories in context
Today’s post continues where “Why you should be using PostGIS trajectories” leaves off. It’s the result of a collaboration with Eva Westermeier. I had the pleasure to supervise her internship at AIT last year and also co-supervised her Master’s thesis [0] on the topic of enriching trajectories with information about their geographic context.
Context-aware analysis of movement data is crucial for different domains and applications, from transport to ecology. While there is a wealth of data, efficient and user-friendly contextual trajectory analysis is still hampered by a lack of appropriate conceptual approaches and practical methods. (Westermeier, 2018)
Part of the work was focused on evaluating different approaches to adding context information from vector datasets to trajectories in PostGIS. For example, adding land cover context to animal movement data or adding information on anchoring and harbor areas to vessel movement data.
Classic point-based model vs. line-based model
The obvious approach is to intersect the trajectory points with context data. This is the classic point data model of contextual trajectories. It’s straightforward to add context information in the point-based model but it also generates large numbers of repeating annotations. In contrast, the line data model using, for example, PostGIS trajectories (LinestringM) is more compact since trajectories can be split into segments at context borders. This creates one annotation per segment and the individual segments are convenient to analyze (as described in part #12).
Spatio-temporal interpolation as provided by the line data model offers additional advantages for the analysis of annotated segments. Contextual segments start and end at the intersection of the trajectory linestring with context polygon borders. This means that there are no gaps like in the point-based model. Consequently, while the point-based model systematically underestimates segment length and duration, the line-based approach offers more meaningful segment length and duration measurements.
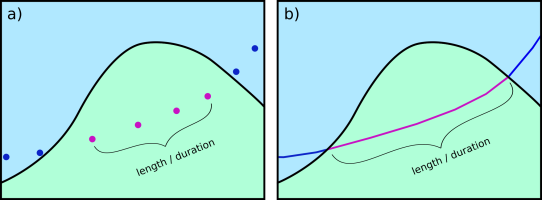
Schematic illustration of a subset of an annotated trajectory in two context classes, a) systematic underestimation of length or duration in the point data model, b) full length or duration between context polygon borders in the line data model (source: Westermeier (2018))
Another issue of the point data model is that brief context changes may be missed or represented by just one point location. This makes it impossible to compute the length or duration of the respective context segment. (Of course, depending on the application, it can be desirable to ignore brief context changes and make the annotation process robust towards irrelevant changes.)

Schematic illustration of context annotation for brief context changes, a) and b)
two variants for the point data model, c) gapless annotation in the line data model (source: Westermeier (2018) based on Buchin et al. (2014))
Beyond annotations, context can also be considered directly in an analysis, for example, when computing distances between trajectories and contextual point objects. In this case, the point-based approach systematically overestimates the distances.
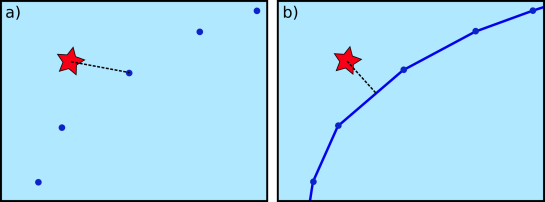
Schematic illustration of distance measurement from a trajectory to an external
object, a) point data model, b) line data model (source: Westermeier (2018))
The above examples show that there are some good reasons to dump the classic point-based model. However, the line-based model is not without its own issues.
Issues
Computing the context annotations for trajectory segments is tricky. The main issue is that ST_Intersection drops the M values. This effectively destroys our trajectories! There are ways to deal with this issue – and the corresponding SQL queries are published in the thesis (p. 38-40) – but it’s a real bummer. Basically, ST_Intersection only provides geometric output. Therefore, we need to reconstruct the temporal information in order to create usable trajectory segments.
Finally, while the line-based model is well suited to add context from other vector data, it is less useful for context data from continuous rasters but that was beyond the scope of this work.
Conclusion
After the promising results of my initial investigations into PostGIS trajectories, I was optimistic that context annotations would be a straightforward add-on. The line-based approach has multiple advantages when it comes to analyzing contextual segments. Unfortunately, generating these contextual segments is much less convenient and also slower than I had hoped. Originally, I had planned to turn this work into a plugin for the Processing toolbox but the results of this work motivated me to look into other solutions. You’ve already seen some of the outcomes in part #20 “Trajectools v1 released!”.
References
This post is part of a series. Read more about movement data in GIS.