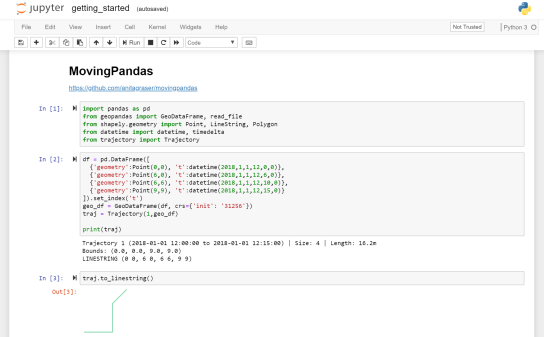
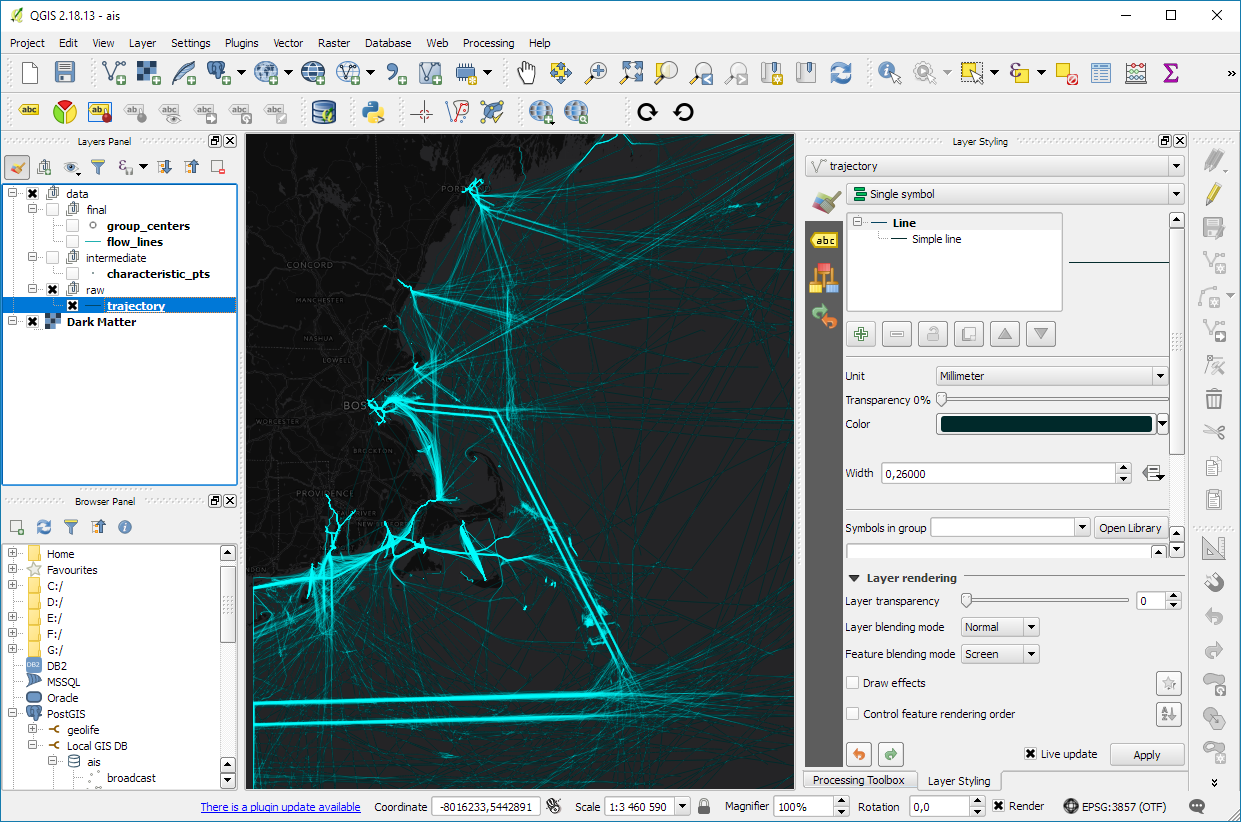
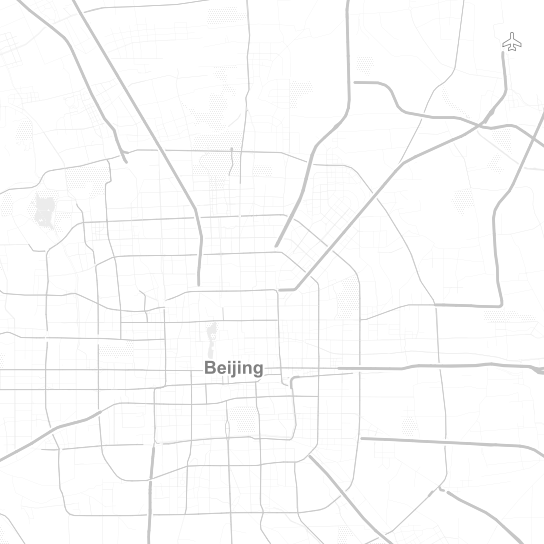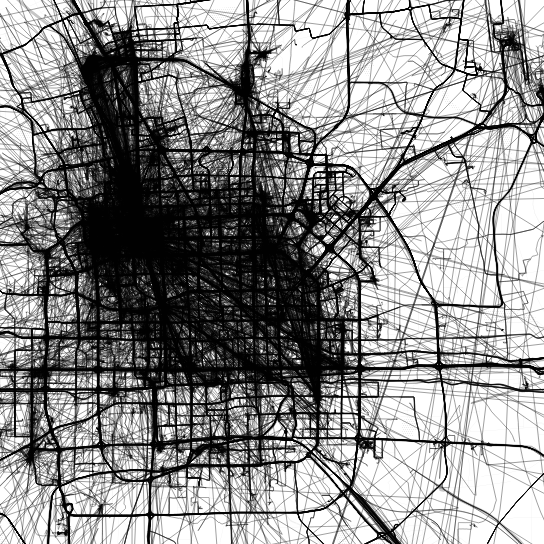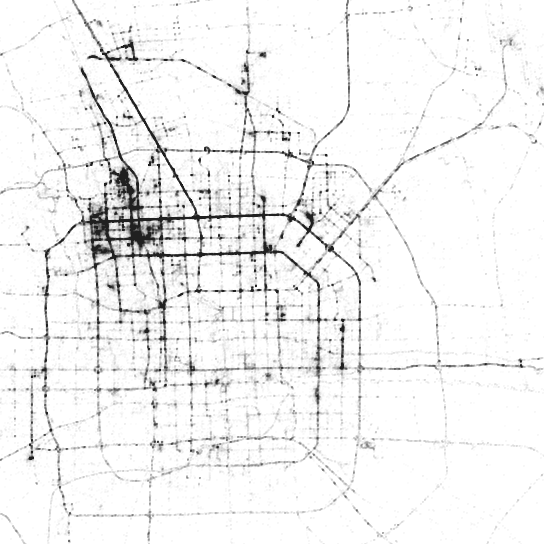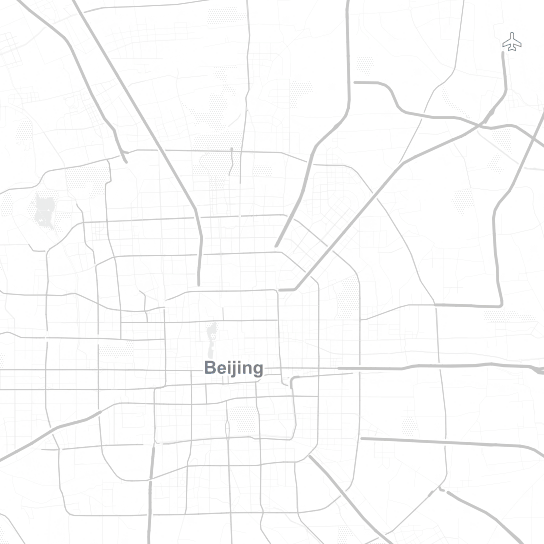
In short: both writing trajectory queries as well as executing them is considerably faster using PostGIS trajectories (as LinestringM) rather than the commonly used point-based approach.
Here are a couple of examples to give you an impression of the differences.
Spoiler alert! Trajectory queries are up to 500 times faster than comparable point-based queries.
A quick look at indexing
In both cases, we have indexed the tracker id, geometry, and time columns to speed up query processing.
The trajectory table has 3 indexes
- gist (time_range)
- gist (track gist_geometry_ops_nd)
- btree (tracker)
The point-based table has 4 indexes
- gist (pt)
- btree (trajectory_id)
- btree (tracker)
- btree (t)
Length
First, let’s see how to determine trajectory length for all observed moving objects (identified by a tracker id).
Using the point-based approach, we first need to ensure that the points are in the correct temporal order, create the lines, and finally sum up their length:
WITH ordered AS (
SELECT trajectory_id, tracker, t, pt
FROM geolife.trajectory_pt
ORDER BY t
), tmp AS (
SELECT trajectory_id, tracker, st_makeline(pt) traj
FROM ordered
GROUP BY trajectory_id, tracker
)
SELECT tracker, round(sum(ST_Length(traj::geography)))
FROM tmp
GROUP BY tracker
ORDER BY tracker
With trajectories, we can go right to computing lengths:
SELECT tracker, round(sum(ST_Length(track::geography)))
FROM geolife.trajectory_ext
GROUP BY tracker
ORDER BY tracker
On my test system, the trajectory query run time is 22.7 sec instead of 43.0 sec for the point-based approach:

Duration
Compared to trajectory length, duration is less complicated in the point-based approach:
WITH tmp AS (
SELECT trajectory_id, tracker, min(t) start_time, max(t) end_time
FROM geolife.trajectory_pt
GROUP BY trajectory_id, tracker
)
SELECT tracker, sum(end_time - start_time)
FROM tmp
GROUP BY tracker
ORDER BY tracker
Still, the trajectory query is less complex and much faster at 31 ms instead of 6.0 sec:
SELECT tracker, sum(upper(time_range) - lower(time_range))
FROM geolife.trajectory_ext
GROUP BY tracker
ORDER BY tracker

Temporal filter
Extracting trajectories that occurred during a certain time frame is another common use case:
WITH tmp AS (
SELECT trajectory_id, tracker, min(t) start_time, max(t) end_time
FROM geolife.trajectory_pt
GROUP BY trajectory_id, tracker
)
SELECT trajectory_id, tracker, start_time, end_time
FROM tmp
WHERE end_time > '2008-11-26 11:00'
AND start_time < '2008-11-26 15:00'
ORDER BY tracker
This point-based query takes 6.0 sec while the shorter trajectory query finishes in 12 ms:
SELECT id, tracker, time_range
FROM geolife.trajectory_ext
WHERE time_range && '[2008-11-26 11:00+1,2008-11-26 15:00+01]'::tstzrange
or equally fast (12 ms) by making use of the n-dimensional index:
WHERE track &&& ST_Collect(
ST_MakePointM(-180, -90, extract(epoch from '2008-11-26 11:00'::timestamptz)),
ST_MakePointM(180, 90, extract(epoch from '2008-11-26 15:00'::timestamptz))
)

Spatial filter
Finally, of course, let’s have a look at spatial filters, for example, trajectories that start in a certain area:
WITH my AS (
SELECT ST_Buffer(ST_SetSRID(ST_MakePoint(116.31894,39.97472),4326),0.0005) areaA
), tmp AS (
SELECT trajectory_id, tracker, min(t) t
FROM geolife.trajectory_pt
GROUP BY trajectory_id, tracker
)
SELECT distinct traj.tracker, traj.trajectory_id
FROM tmp
JOIN geolife.trajectory_pt traj
ON tmp.trajectory_id = traj.trajectory_id AND traj.t = tmp.t
JOIN my
ON ST_Within(traj.pt, my.areaA)
This point-based query takes 6.0 sec while the shorter trajectory query finishes in 488 ms:
WITH my AS (
SELECT ST_Buffer(ST_SetSRID(ST_MakePoint(116.31894, 39.97472),4326),0.0005) areaA
)
SELECT id, tracker, ST_AsText(track)
FROM geolife.trajectory_ext
JOIN my
ON areaA && track
AND ST_Within(ST_StartPoint(track), areaA)
For more generic “does this trajectory intersect another geometry”, the points can also be aggregated to a linestring on the fly but that takes 21.9 sec:

I’ll be presenting more work on PostGIS trajectories at GI_Forum in Salzburg in July. In the talk, I’ll also have a look at the custom PG-Trajectory datatype. Here’s the full open-access paper:
Graser, A. (2018) Evaluating Spatio-temporal Data Models for Trajectories in PostGIS Databases. GI_Forum ‒ Journal of Geographic Information Science, 1-2018, 16-33. DOI: 10.1553/giscience2018_01_s16.
You can find my fork of the PG-Trajectory project – including all necessary fixes – on Bitbucket.
This post is part of a series. Read more about movement data in GIS.